Algorithmic Signal AnalyzerMeet Algorithmic Signal Analyzer (ASA) v1: A revolutionary tool that ushers in a new era of clarity and precision for both short-term and long-term market analysis, elevating your strategies to the next level.
ASA is an advanced TradingView indicator designed to filter out noise and enhance signal detection using mathematical models. By processing price movements within defined standard deviation ranges, ASA produces a smoothed analysis based on a Weighted Moving Average (WMA). The Volatility Filter ensures that only relevant price data is retained, removing outliers and improving analytical accuracy.
While ASA provides significant analytical advantages, it’s essential to understand its capabilities in both short-term and long-term use cases. For short-term trading, ASA excels at capturing swift opportunities by highlighting immediate trend changes. Conversely, in long-term trading, it reveals the overall direction of market trends, enabling traders to align their strategies with prevailing conditions.
Despite these benefits, traders must remember that ASA is not designed for precise trade execution systems where accuracy in timing and price levels is critical. Its focus is on analysis rather than order management. The distinction is crucial: ASA helps interpret price action effectively but may not account for real-time market factors such as slippage or execution delays.
Features and Functionality
ASA integrates multiple tools to enhance its analytical capabilities:
Customizable Moving Averages: SMA, EMA, and WMA options allow users to tailor the indicator to their trading style.
Signal Detection: Identifies bullish and bearish trends using the Relative Exponential Moving Average (REMA) and marks potential buy/sell opportunities.
Visual Aids: Color-coded trend lines (green for upward, red for downward) simplify interpretation.
Alert System: Notifications for trend swings and reversals enable timely decision-making.
Notes on Usage
ASA’s effectiveness depends on the context in which it is applied. Traders should carefully consider the trade-offs between analysis and execution.
Results may vary depending on market conditions and chart types. Backtesting with ASA on standard charts provides more reliable insights compared to non-standard chart types.
Short-term use focuses on rapid trend recognition, while long-term application emphasizes understanding broader market movements.
Takeaways
ASA is not a tool for precise trade execution but a powerful aid for interpreting price trends.
For short-term trading, ASA identifies quick opportunities, while for long-term strategies, it highlights trend directions.
Understanding ASA’s limitations and strengths is key to maximizing its utility.
ASA is a robust solution for traders seeking to filter noise, enhance analytical clarity, and align their strategies with market movements, whether for short bursts of activity or sustained trading goals.
ابحث في النصوص البرمجية عن "algo"
Algo Structure [ValiantTrader_]Explanation of the "Algo Structure" Trading Indicator
This Pine Script indicator, created by ValiantTrader_, is a multi-timeframe swing analysis tool that helps traders identify key price levels and market structure across different timeframes. Here's how it works and how traders can use it:
Core Components
1. Multi-Timeframe Swing Analysis
The indicator tracks swing highs and lows across:
The current chart timeframe
A higher timeframe (weekly by default)
An even higher timeframe (monthly by default)
2. Swing Detection Logic
Current timeframe swings: Identified when price makes a 3-bar high/low pattern
Higher timeframe swings: Uses the highest high/lowest low of the last 3 bars on those timeframes
3. Visual Elements
Horizontal lines marking swing points
Labels showing the timeframe and percentage distance from current price
An information table summarizing key levels
How Traders Use This Indicator
1. Identifying Key Levels
The indicator draws recent swing highs (red) and swing lows (green)
These levels act as potential support/resistance areas
Traders watch for price reactions at these levels
2. Multi-Timeframe Analysis
By seeing swings from higher timeframes (weekly, monthly), traders can:
Identify more significant support/resistance zones
Understand the broader market context
Spot confluence areas where multiple timeframes align
3. Measuring Price Distance
The percentage display shows how far current price is from each swing level
Helps assess potential reward/risk at current levels
Shows volatility between swings (wider % = more volatile moves)
4. Table Summary
The info table provides a quick reference for:
Exact price levels of swings
Percentage ranges between highs and lows
Comparison across timeframes
5. Trading Applications
Breakout trading: When price moves beyond a swing high/low
Mean reversion: Trading bounces between swing levels
Trend confirmation: Higher highs/lows in multiple timeframes confirm trends
Support/resistance trading: Entering trades at swing levels with other confirmation
Customization Options
Traders can adjust:
The higher timeframes analyzed
Whether to show the timeframe labels
Whether to display swing levels
Whether to show the info table
The indicator also includes price alerts for new swing highs/lows on the current timeframe, allowing traders to get notifications when market structure changes.
This tool is particularly valuable for traders who incorporate multi-timeframe analysis into their strategy, helping them visualize important price levels across different time perspectives

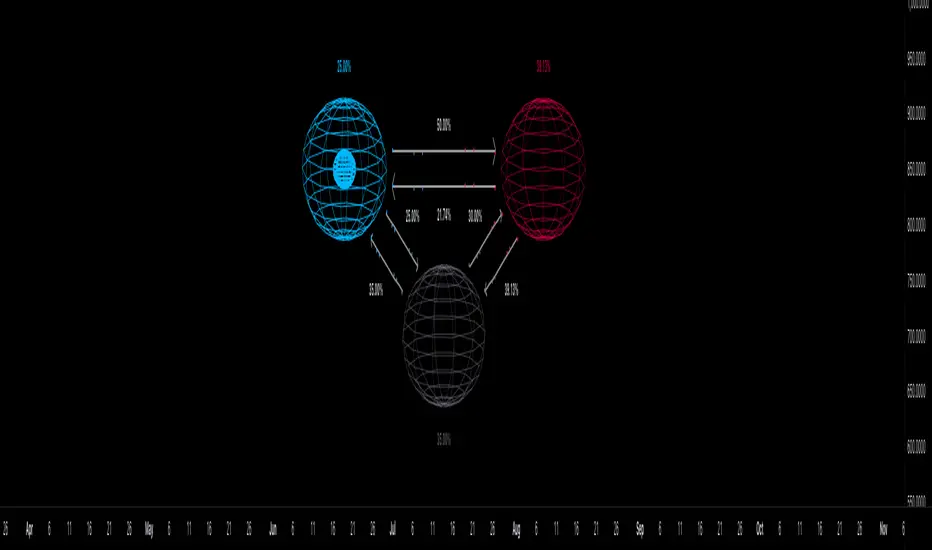
Markov Chain [3D] | FractalystWhat exactly is a Markov Chain?
This indicator uses a Markov Chain model to analyze, quantify, and visualize the transitions between market regimes (Bull, Bear, Neutral) on your chart. It dynamically detects these regimes in real-time, calculates transition probabilities, and displays them as animated 3D spheres and arrows, giving traders intuitive insight into current and future market conditions.
How does a Markov Chain work, and how should I read this spheres-and-arrows diagram?
Think of three weather modes: Sunny, Rainy, Cloudy.
Each sphere is one mode. The loop on a sphere means “stay the same next step” (e.g., Sunny again tomorrow).
The arrows leaving a sphere show where things usually go next if they change (e.g., Sunny moving to Cloudy).
Some paths matter more than others. A more prominent loop means the current mode tends to persist. A more prominent outgoing arrow means a change to that destination is the usual next step.
Direction isn’t symmetric: moving Sunny→Cloudy can behave differently than Cloudy→Sunny.
Now relabel the spheres to markets: Bull, Bear, Neutral.
Spheres: market regimes (uptrend, downtrend, range).
Self‑loop: tendency for the current regime to continue on the next bar.
Arrows: the most common next regime if a switch happens.
How to read: Start at the sphere that matches current bar state. If the loop stands out, expect continuation. If one outgoing path stands out, that switch is the typical next step. Opposite directions can differ (Bear→Neutral doesn’t have to match Neutral→Bear).
What states and transitions are shown?
The three market states visualized are:
Bullish (Bull): Upward or strong-market regime.
Bearish (Bear): Downward or weak-market regime.
Neutral: Sideways or range-bound regime.
Bidirectional animated arrows and probability labels show how likely the market is to move from one regime to another (e.g., Bull → Bear or Neutral → Bull).
How does the regime detection system work?
You can use either built-in price returns (based on adaptive Z-score normalization) or supply three custom indicators (such as volume, oscillators, etc.).
Values are statistically normalized (Z-scored) over a configurable lookback period.
The normalized outputs are classified into Bull, Bear, or Neutral zones.
If using three indicators, their regime signals are averaged and smoothed for robustness.
How are transition probabilities calculated?
On every confirmed bar, the algorithm tracks the sequence of detected market states, then builds a rolling window of transitions.
The code maintains a transition count matrix for all regime pairs (e.g., Bull → Bear).
Transition probabilities are extracted for each possible state change using Laplace smoothing for numerical stability, and frequently updated in real-time.
What is unique about the visualization?
3D animated spheres represent each regime and change visually when active.
Animated, bidirectional arrows reveal transition probabilities and allow you to see both dominant and less likely regime flows.
Particles (moving dots) animate along the arrows, enhancing the perception of regime flow direction and speed.
All elements dynamically update with each new price bar, providing a live market map in an intuitive, engaging format.
Can I use custom indicators for regime classification?
Yes! Enable the "Custom Indicators" switch and select any three chart series as inputs. These will be normalized and combined (each with equal weight), broadening the regime classification beyond just price-based movement.
What does the “Lookback Period” control?
Lookback Period (default: 100) sets how much historical data builds the probability matrix. Shorter periods adapt faster to regime changes but may be noisier. Longer periods are more stable but slower to adapt.
How is this different from a Hidden Markov Model (HMM)?
It sets the window for both regime detection and probability calculations. Lower values make the system more reactive, but potentially noisier. Higher values smooth estimates and make the system more robust.
How is this Markov Chain different from a Hidden Markov Model (HMM)?
Markov Chain (as here): All market regimes (Bull, Bear, Neutral) are directly observable on the chart. The transition matrix is built from actual detected regimes, keeping the model simple and interpretable.
Hidden Markov Model: The actual regimes are unobservable ("hidden") and must be inferred from market output or indicator "emissions" using statistical learning algorithms. HMMs are more complex, can capture more subtle structure, but are harder to visualize and require additional machine learning steps for training.
A standard Markov Chain models transitions between observable states using a simple transition matrix, while a Hidden Markov Model assumes the true states are hidden (latent) and must be inferred from observable “emissions” like price or volume data. In practical terms, a Markov Chain is transparent and easier to implement and interpret; an HMM is more expressive but requires statistical inference to estimate hidden states from data.
Markov Chain: states are observable; you directly count or estimate transition probabilities between visible states. This makes it simpler, faster, and easier to validate and tune.
HMM: states are hidden; you only observe emissions generated by those latent states. Learning involves machine learning/statistical algorithms (commonly Baum–Welch/EM for training and Viterbi for decoding) to infer both the transition dynamics and the most likely hidden state sequence from data.
How does the indicator avoid “repainting” or look-ahead bias?
All regime changes and matrix updates happen only on confirmed (closed) bars, so no future data is leaked, ensuring reliable real-time operation.
Are there practical tuning tips?
Tune the Lookback Period for your asset/timeframe: shorter for fast markets, longer for stability.
Use custom indicators if your asset has unique regime drivers.
Watch for rapid changes in transition probabilities as early warning of a possible regime shift.
Who is this indicator for?
Quants and quantitative researchers exploring probabilistic market modeling, especially those interested in regime-switching dynamics and Markov models.
Programmers and system developers who need a probabilistic regime filter for systematic and algorithmic backtesting:
The Markov Chain indicator is ideally suited for programmatic integration via its bias output (1 = Bull, 0 = Neutral, -1 = Bear).
Although the visualization is engaging, the core output is designed for automated, rules-based workflows—not for discretionary/manual trading decisions.
Developers can connect the indicator’s output directly to their Pine Script logic (using input.source()), allowing rapid and robust backtesting of regime-based strategies.
It acts as a plug-and-play regime filter: simply plug the bias output into your entry/exit logic, and you have a scientifically robust, probabilistically-derived signal for filtering, timing, position sizing, or risk regimes.
The MC's output is intentionally "trinary" (1/0/-1), focusing on clear regime states for unambiguous decision-making in code. If you require nuanced, multi-probability or soft-label state vectors, consider expanding the indicator or stacking it with a probability-weighted logic layer in your scripting.
Because it avoids subjectivity, this approach is optimal for systematic quants, algo developers building backtested, repeatable strategies based on probabilistic regime analysis.
What's the mathematical foundation behind this?
The mathematical foundation behind this Markov Chain indicator—and probabilistic regime detection in finance—draws from two principal models: the (standard) Markov Chain and the Hidden Markov Model (HMM).
How to use this indicator programmatically?
The Markov Chain indicator automatically exports a bias value (+1 for Bullish, -1 for Bearish, 0 for Neutral) as a plot visible in the Data Window. This allows you to integrate its regime signal into your own scripts and strategies for backtesting, automation, or live trading.
Step-by-Step Integration with Pine Script (input.source)
Add the Markov Chain indicator to your chart.
This must be done first, since your custom script will "pull" the bias signal from the indicator's plot.
In your strategy, create an input using input.source()
Example:
//@version=5
strategy("MC Bias Strategy Example")
mcBias = input.source(close, "MC Bias Source")
After saving, go to your script’s settings. For the “MC Bias Source” input, select the plot/output of the Markov Chain indicator (typically its bias plot).
Use the bias in your trading logic
Example (long only on Bull, flat otherwise):
if mcBias == 1
strategy.entry("Long", strategy.long)
else
strategy.close("Long")
For more advanced workflows, combine mcBias with additional filters or trailing stops.
How does this work behind-the-scenes?
TradingView’s input.source() lets you use any plot from another indicator as a real-time, “live” data feed in your own script (source).
The selected bias signal is available to your Pine code as a variable, enabling logical decisions based on regime (trend-following, mean-reversion, etc.).
This enables powerful strategy modularity : decouple regime detection from entry/exit logic, allowing fast experimentation without rewriting core signal code.
Integrating 45+ Indicators with Your Markov Chain — How & Why
The Enhanced Custom Indicators Export script exports a massive suite of over 45 technical indicators—ranging from classic momentum (RSI, MACD, Stochastic, etc.) to trend, volume, volatility, and oscillator tools—all pre-calculated, centered/scaled, and available as plots.
// Enhanced Custom Indicators Export - 45 Technical Indicators
// Comprehensive technical analysis suite for advanced market regime detection
//@version=6
indicator('Enhanced Custom Indicators Export | Fractalyst', shorttitle='Enhanced CI Export', overlay=false, scale=scale.right, max_labels_count=500, max_lines_count=500)
// |----- Input Parameters -----| //
momentum_group = "Momentum Indicators"
trend_group = "Trend Indicators"
volume_group = "Volume Indicators"
volatility_group = "Volatility Indicators"
oscillator_group = "Oscillator Indicators"
display_group = "Display Settings"
// Common lengths
length_14 = input.int(14, "Standard Length (14)", minval=1, maxval=100, group=momentum_group)
length_20 = input.int(20, "Medium Length (20)", minval=1, maxval=200, group=trend_group)
length_50 = input.int(50, "Long Length (50)", minval=1, maxval=200, group=trend_group)
// Display options
show_table = input.bool(true, "Show Values Table", group=display_group)
table_size = input.string("Small", "Table Size", options= , group=display_group)
// |----- MOMENTUM INDICATORS (15 indicators) -----| //
// 1. RSI (Relative Strength Index)
rsi_14 = ta.rsi(close, length_14)
rsi_centered = rsi_14 - 50
// 2. Stochastic Oscillator
stoch_k = ta.stoch(close, high, low, length_14)
stoch_d = ta.sma(stoch_k, 3)
stoch_centered = stoch_k - 50
// 3. Williams %R
williams_r = ta.stoch(close, high, low, length_14) - 100
// 4. MACD (Moving Average Convergence Divergence)
= ta.macd(close, 12, 26, 9)
// 5. Momentum (Rate of Change)
momentum = ta.mom(close, length_14)
momentum_pct = (momentum / close ) * 100
// 6. Rate of Change (ROC)
roc = ta.roc(close, length_14)
// 7. Commodity Channel Index (CCI)
cci = ta.cci(close, length_20)
// 8. Money Flow Index (MFI)
mfi = ta.mfi(close, length_14)
mfi_centered = mfi - 50
// 9. Awesome Oscillator (AO)
ao = ta.sma(hl2, 5) - ta.sma(hl2, 34)
// 10. Accelerator Oscillator (AC)
ac = ao - ta.sma(ao, 5)
// 11. Chande Momentum Oscillator (CMO)
cmo = ta.cmo(close, length_14)
// 12. Detrended Price Oscillator (DPO)
dpo = close - ta.sma(close, length_20)
// 13. Price Oscillator (PPO)
ppo = ta.sma(close, 12) - ta.sma(close, 26)
ppo_pct = (ppo / ta.sma(close, 26)) * 100
// 14. TRIX
trix_ema1 = ta.ema(close, length_14)
trix_ema2 = ta.ema(trix_ema1, length_14)
trix_ema3 = ta.ema(trix_ema2, length_14)
trix = ta.roc(trix_ema3, 1) * 10000
// 15. Klinger Oscillator
klinger = ta.ema(volume * (high + low + close) / 3, 34) - ta.ema(volume * (high + low + close) / 3, 55)
// 16. Fisher Transform
fisher_hl2 = 0.5 * (hl2 - ta.lowest(hl2, 10)) / (ta.highest(hl2, 10) - ta.lowest(hl2, 10)) - 0.25
fisher = 0.5 * math.log((1 + fisher_hl2) / (1 - fisher_hl2))
// 17. Stochastic RSI
stoch_rsi = ta.stoch(rsi_14, rsi_14, rsi_14, length_14)
stoch_rsi_centered = stoch_rsi - 50
// 18. Relative Vigor Index (RVI)
rvi_num = ta.swma(close - open)
rvi_den = ta.swma(high - low)
rvi = rvi_den != 0 ? rvi_num / rvi_den : 0
// 19. Balance of Power (BOP)
bop = (close - open) / (high - low)
// |----- TREND INDICATORS (10 indicators) -----| //
// 20. Simple Moving Average Momentum
sma_20 = ta.sma(close, length_20)
sma_momentum = ((close - sma_20) / sma_20) * 100
// 21. Exponential Moving Average Momentum
ema_20 = ta.ema(close, length_20)
ema_momentum = ((close - ema_20) / ema_20) * 100
// 22. Parabolic SAR
sar = ta.sar(0.02, 0.02, 0.2)
sar_trend = close > sar ? 1 : -1
// 23. Linear Regression Slope
lr_slope = ta.linreg(close, length_20, 0) - ta.linreg(close, length_20, 1)
// 24. Moving Average Convergence (MAC)
mac = ta.sma(close, 10) - ta.sma(close, 30)
// 25. Trend Intensity Index (TII)
tii_sum = 0.0
for i = 1 to length_20
tii_sum += close > close ? 1 : 0
tii = (tii_sum / length_20) * 100
// 26. Ichimoku Cloud Components
ichimoku_tenkan = (ta.highest(high, 9) + ta.lowest(low, 9)) / 2
ichimoku_kijun = (ta.highest(high, 26) + ta.lowest(low, 26)) / 2
ichimoku_signal = ichimoku_tenkan > ichimoku_kijun ? 1 : -1
// 27. MESA Adaptive Moving Average (MAMA)
mama_alpha = 2.0 / (length_20 + 1)
mama = ta.ema(close, length_20)
mama_momentum = ((close - mama) / mama) * 100
// 28. Zero Lag Exponential Moving Average (ZLEMA)
zlema_lag = math.round((length_20 - 1) / 2)
zlema_data = close + (close - close )
zlema = ta.ema(zlema_data, length_20)
zlema_momentum = ((close - zlema) / zlema) * 100
// |----- VOLUME INDICATORS (6 indicators) -----| //
// 29. On-Balance Volume (OBV)
obv = ta.obv
// 30. Volume Rate of Change (VROC)
vroc = ta.roc(volume, length_14)
// 31. Price Volume Trend (PVT)
pvt = ta.pvt
// 32. Negative Volume Index (NVI)
nvi = 0.0
nvi := volume < volume ? nvi + ((close - close ) / close ) * nvi : nvi
// 33. Positive Volume Index (PVI)
pvi = 0.0
pvi := volume > volume ? pvi + ((close - close ) / close ) * pvi : pvi
// 34. Volume Oscillator
vol_osc = ta.sma(volume, 5) - ta.sma(volume, 10)
// 35. Ease of Movement (EOM)
eom_distance = high - low
eom_box_height = volume / 1000000
eom = eom_box_height != 0 ? eom_distance / eom_box_height : 0
eom_sma = ta.sma(eom, length_14)
// 36. Force Index
force_index = volume * (close - close )
force_index_sma = ta.sma(force_index, length_14)
// |----- VOLATILITY INDICATORS (10 indicators) -----| //
// 37. Average True Range (ATR)
atr = ta.atr(length_14)
atr_pct = (atr / close) * 100
// 38. Bollinger Bands Position
bb_basis = ta.sma(close, length_20)
bb_dev = 2.0 * ta.stdev(close, length_20)
bb_upper = bb_basis + bb_dev
bb_lower = bb_basis - bb_dev
bb_position = bb_dev != 0 ? (close - bb_basis) / bb_dev : 0
bb_width = bb_dev != 0 ? (bb_upper - bb_lower) / bb_basis * 100 : 0
// 39. Keltner Channels Position
kc_basis = ta.ema(close, length_20)
kc_range = ta.ema(ta.tr, length_20)
kc_upper = kc_basis + (2.0 * kc_range)
kc_lower = kc_basis - (2.0 * kc_range)
kc_position = kc_range != 0 ? (close - kc_basis) / kc_range : 0
// 40. Donchian Channels Position
dc_upper = ta.highest(high, length_20)
dc_lower = ta.lowest(low, length_20)
dc_basis = (dc_upper + dc_lower) / 2
dc_position = (dc_upper - dc_lower) != 0 ? (close - dc_basis) / (dc_upper - dc_lower) : 0
// 41. Standard Deviation
std_dev = ta.stdev(close, length_20)
std_dev_pct = (std_dev / close) * 100
// 42. Relative Volatility Index (RVI)
rvi_up = ta.stdev(close > close ? close : 0, length_14)
rvi_down = ta.stdev(close < close ? close : 0, length_14)
rvi_total = rvi_up + rvi_down
rvi_volatility = rvi_total != 0 ? (rvi_up / rvi_total) * 100 : 50
// 43. Historical Volatility
hv_returns = math.log(close / close )
hv = ta.stdev(hv_returns, length_20) * math.sqrt(252) * 100
// 44. Garman-Klass Volatility
gk_vol = math.log(high/low) * math.log(high/low) - (2*math.log(2)-1) * math.log(close/open) * math.log(close/open)
gk_volatility = math.sqrt(ta.sma(gk_vol, length_20)) * 100
// 45. Parkinson Volatility
park_vol = math.log(high/low) * math.log(high/low)
parkinson = math.sqrt(ta.sma(park_vol, length_20) / (4 * math.log(2))) * 100
// 46. Rogers-Satchell Volatility
rs_vol = math.log(high/close) * math.log(high/open) + math.log(low/close) * math.log(low/open)
rogers_satchell = math.sqrt(ta.sma(rs_vol, length_20)) * 100
// |----- OSCILLATOR INDICATORS (5 indicators) -----| //
// 47. Elder Ray Index
elder_bull = high - ta.ema(close, 13)
elder_bear = low - ta.ema(close, 13)
elder_power = elder_bull + elder_bear
// 48. Schaff Trend Cycle (STC)
stc_macd = ta.ema(close, 23) - ta.ema(close, 50)
stc_k = ta.stoch(stc_macd, stc_macd, stc_macd, 10)
stc_d = ta.ema(stc_k, 3)
stc = ta.stoch(stc_d, stc_d, stc_d, 10)
// 49. Coppock Curve
coppock_roc1 = ta.roc(close, 14)
coppock_roc2 = ta.roc(close, 11)
coppock = ta.wma(coppock_roc1 + coppock_roc2, 10)
// 50. Know Sure Thing (KST)
kst_roc1 = ta.roc(close, 10)
kst_roc2 = ta.roc(close, 15)
kst_roc3 = ta.roc(close, 20)
kst_roc4 = ta.roc(close, 30)
kst = ta.sma(kst_roc1, 10) + 2*ta.sma(kst_roc2, 10) + 3*ta.sma(kst_roc3, 10) + 4*ta.sma(kst_roc4, 15)
// 51. Percentage Price Oscillator (PPO)
ppo_line = ((ta.ema(close, 12) - ta.ema(close, 26)) / ta.ema(close, 26)) * 100
ppo_signal = ta.ema(ppo_line, 9)
ppo_histogram = ppo_line - ppo_signal
// |----- PLOT MAIN INDICATORS -----| //
// Plot key momentum indicators
plot(rsi_centered, title="01_RSI_Centered", color=color.purple, linewidth=1)
plot(stoch_centered, title="02_Stoch_Centered", color=color.blue, linewidth=1)
plot(williams_r, title="03_Williams_R", color=color.red, linewidth=1)
plot(macd_histogram, title="04_MACD_Histogram", color=color.orange, linewidth=1)
plot(cci, title="05_CCI", color=color.green, linewidth=1)
// Plot trend indicators
plot(sma_momentum, title="06_SMA_Momentum", color=color.navy, linewidth=1)
plot(ema_momentum, title="07_EMA_Momentum", color=color.maroon, linewidth=1)
plot(sar_trend, title="08_SAR_Trend", color=color.teal, linewidth=1)
plot(lr_slope, title="09_LR_Slope", color=color.lime, linewidth=1)
plot(mac, title="10_MAC", color=color.fuchsia, linewidth=1)
// Plot volatility indicators
plot(atr_pct, title="11_ATR_Pct", color=color.yellow, linewidth=1)
plot(bb_position, title="12_BB_Position", color=color.aqua, linewidth=1)
plot(kc_position, title="13_KC_Position", color=color.olive, linewidth=1)
plot(std_dev_pct, title="14_StdDev_Pct", color=color.silver, linewidth=1)
plot(bb_width, title="15_BB_Width", color=color.gray, linewidth=1)
// Plot volume indicators
plot(vroc, title="16_VROC", color=color.blue, linewidth=1)
plot(eom_sma, title="17_EOM", color=color.red, linewidth=1)
plot(vol_osc, title="18_Vol_Osc", color=color.green, linewidth=1)
plot(force_index_sma, title="19_Force_Index", color=color.orange, linewidth=1)
plot(obv, title="20_OBV", color=color.purple, linewidth=1)
// Plot additional oscillators
plot(ao, title="21_Awesome_Osc", color=color.navy, linewidth=1)
plot(cmo, title="22_CMO", color=color.maroon, linewidth=1)
plot(dpo, title="23_DPO", color=color.teal, linewidth=1)
plot(trix, title="24_TRIX", color=color.lime, linewidth=1)
plot(fisher, title="25_Fisher", color=color.fuchsia, linewidth=1)
// Plot more momentum indicators
plot(mfi_centered, title="26_MFI_Centered", color=color.yellow, linewidth=1)
plot(ac, title="27_AC", color=color.aqua, linewidth=1)
plot(ppo_pct, title="28_PPO_Pct", color=color.olive, linewidth=1)
plot(stoch_rsi_centered, title="29_StochRSI_Centered", color=color.silver, linewidth=1)
plot(klinger, title="30_Klinger", color=color.gray, linewidth=1)
// Plot trend continuation
plot(tii, title="31_TII", color=color.blue, linewidth=1)
plot(ichimoku_signal, title="32_Ichimoku_Signal", color=color.red, linewidth=1)
plot(mama_momentum, title="33_MAMA_Momentum", color=color.green, linewidth=1)
plot(zlema_momentum, title="34_ZLEMA_Momentum", color=color.orange, linewidth=1)
plot(bop, title="35_BOP", color=color.purple, linewidth=1)
// Plot volume continuation
plot(nvi, title="36_NVI", color=color.navy, linewidth=1)
plot(pvi, title="37_PVI", color=color.maroon, linewidth=1)
plot(momentum_pct, title="38_Momentum_Pct", color=color.teal, linewidth=1)
plot(roc, title="39_ROC", color=color.lime, linewidth=1)
plot(rvi, title="40_RVI", color=color.fuchsia, linewidth=1)
// Plot volatility continuation
plot(dc_position, title="41_DC_Position", color=color.yellow, linewidth=1)
plot(rvi_volatility, title="42_RVI_Volatility", color=color.aqua, linewidth=1)
plot(hv, title="43_Historical_Vol", color=color.olive, linewidth=1)
plot(gk_volatility, title="44_GK_Volatility", color=color.silver, linewidth=1)
plot(parkinson, title="45_Parkinson_Vol", color=color.gray, linewidth=1)
// Plot final oscillators
plot(rogers_satchell, title="46_RS_Volatility", color=color.blue, linewidth=1)
plot(elder_power, title="47_Elder_Power", color=color.red, linewidth=1)
plot(stc, title="48_STC", color=color.green, linewidth=1)
plot(coppock, title="49_Coppock", color=color.orange, linewidth=1)
plot(kst, title="50_KST", color=color.purple, linewidth=1)
// Plot final indicators
plot(ppo_histogram, title="51_PPO_Histogram", color=color.navy, linewidth=1)
plot(pvt, title="52_PVT", color=color.maroon, linewidth=1)
// |----- Reference Lines -----| //
hline(0, "Zero Line", color=color.gray, linestyle=hline.style_dashed, linewidth=1)
hline(50, "Midline", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(-50, "Lower Midline", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(25, "Upper Threshold", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
hline(-25, "Lower Threshold", color=color.gray, linestyle=hline.style_dotted, linewidth=1)
// |----- Enhanced Information Table -----| //
if show_table and barstate.islast
table_position = position.top_right
table_text_size = table_size == "Tiny" ? size.tiny : table_size == "Small" ? size.small : size.normal
var table info_table = table.new(table_position, 3, 18, bgcolor=color.new(color.white, 85), border_width=1, border_color=color.gray)
// Headers
table.cell(info_table, 0, 0, 'Category', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
table.cell(info_table, 1, 0, 'Indicator', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
table.cell(info_table, 2, 0, 'Value', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.blue, 70))
// Key Momentum Indicators
table.cell(info_table, 0, 1, 'MOMENTUM', text_color=color.purple, text_size=table_text_size, bgcolor=color.new(color.purple, 90))
table.cell(info_table, 1, 1, 'RSI Centered', text_color=color.purple, text_size=table_text_size)
table.cell(info_table, 2, 1, str.tostring(rsi_centered, '0.00'), text_color=color.purple, text_size=table_text_size)
table.cell(info_table, 0, 2, '', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 1, 2, 'Stoch Centered', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 2, str.tostring(stoch_centered, '0.00'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 3, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 3, 'Williams %R', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 3, str.tostring(williams_r, '0.00'), text_color=color.red, text_size=table_text_size)
table.cell(info_table, 0, 4, '', text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 1, 4, 'MACD Histogram', text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 2, 4, str.tostring(macd_histogram, '0.000'), text_color=color.orange, text_size=table_text_size)
table.cell(info_table, 0, 5, '', text_color=color.green, text_size=table_text_size)
table.cell(info_table, 1, 5, 'CCI', text_color=color.green, text_size=table_text_size)
table.cell(info_table, 2, 5, str.tostring(cci, '0.00'), text_color=color.green, text_size=table_text_size)
// Key Trend Indicators
table.cell(info_table, 0, 6, 'TREND', text_color=color.navy, text_size=table_text_size, bgcolor=color.new(color.navy, 90))
table.cell(info_table, 1, 6, 'SMA Momentum %', text_color=color.navy, text_size=table_text_size)
table.cell(info_table, 2, 6, str.tostring(sma_momentum, '0.00'), text_color=color.navy, text_size=table_text_size)
table.cell(info_table, 0, 7, '', text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 1, 7, 'EMA Momentum %', text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 2, 7, str.tostring(ema_momentum, '0.00'), text_color=color.maroon, text_size=table_text_size)
table.cell(info_table, 0, 8, '', text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 1, 8, 'SAR Trend', text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 2, 8, str.tostring(sar_trend, '0'), text_color=color.teal, text_size=table_text_size)
table.cell(info_table, 0, 9, '', text_color=color.lime, text_size=table_text_size)
table.cell(info_table, 1, 9, 'Linear Regression', text_color=color.lime, text_size=table_text_size)
table.cell(info_table, 2, 9, str.tostring(lr_slope, '0.000'), text_color=color.lime, text_size=table_text_size)
// Key Volatility Indicators
table.cell(info_table, 0, 10, 'VOLATILITY', text_color=color.yellow, text_size=table_text_size, bgcolor=color.new(color.yellow, 90))
table.cell(info_table, 1, 10, 'ATR %', text_color=color.yellow, text_size=table_text_size)
table.cell(info_table, 2, 10, str.tostring(atr_pct, '0.00'), text_color=color.yellow, text_size=table_text_size)
table.cell(info_table, 0, 11, '', text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 1, 11, 'BB Position', text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 2, 11, str.tostring(bb_position, '0.00'), text_color=color.aqua, text_size=table_text_size)
table.cell(info_table, 0, 12, '', text_color=color.olive, text_size=table_text_size)
table.cell(info_table, 1, 12, 'KC Position', text_color=color.olive, text_size=table_text_size)
table.cell(info_table, 2, 12, str.tostring(kc_position, '0.00'), text_color=color.olive, text_size=table_text_size)
// Key Volume Indicators
table.cell(info_table, 0, 13, 'VOLUME', text_color=color.blue, text_size=table_text_size, bgcolor=color.new(color.blue, 90))
table.cell(info_table, 1, 13, 'Volume ROC', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 13, str.tostring(vroc, '0.00'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 14, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 14, 'EOM', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 14, str.tostring(eom_sma, '0.000'), text_color=color.red, text_size=table_text_size)
// Key Oscillators
table.cell(info_table, 0, 15, 'OSCILLATORS', text_color=color.purple, text_size=table_text_size, bgcolor=color.new(color.purple, 90))
table.cell(info_table, 1, 15, 'Awesome Osc', text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 2, 15, str.tostring(ao, '0.000'), text_color=color.blue, text_size=table_text_size)
table.cell(info_table, 0, 16, '', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 1, 16, 'Fisher Transform', text_color=color.red, text_size=table_text_size)
table.cell(info_table, 2, 16, str.tostring(fisher, '0.000'), text_color=color.red, text_size=table_text_size)
// Summary Statistics
table.cell(info_table, 0, 17, 'SUMMARY', text_color=color.black, text_size=table_text_size, bgcolor=color.new(color.gray, 70))
table.cell(info_table, 1, 17, 'Total Indicators: 52', text_color=color.black, text_size=table_text_size)
regime_color = rsi_centered > 10 ? color.green : rsi_centered < -10 ? color.red : color.gray
regime_text = rsi_centered > 10 ? "BULLISH" : rsi_centered < -10 ? "BEARISH" : "NEUTRAL"
table.cell(info_table, 2, 17, regime_text, text_color=regime_color, text_size=table_text_size)
This makes it the perfect “indicator backbone” for quantitative and systematic traders who want to prototype, combine, and test new regime detection models—especially in combination with the Markov Chain indicator.
How to use this script with the Markov Chain for research and backtesting:
Add the Enhanced Indicator Export to your chart.
Every calculated indicator is available as an individual data stream.
Connect the indicator(s) you want as custom input(s) to the Markov Chain’s “Custom Indicators” option.
In the Markov Chain indicator’s settings, turn ON the custom indicator mode.
For each of the three custom indicator inputs, select the exported plot from the Enhanced Export script—the menu lists all 45+ signals by name.
This creates a powerful, modular regime-detection engine where you can mix-and-match momentum, trend, volume, or custom combinations for advanced filtering.
Backtest regime logic directly.
Once you’ve connected your chosen indicators, the Markov Chain script performs regime detection (Bull/Neutral/Bear) based on your selected features—not just price returns.
The regime detection is robust, automatically normalized (using Z-score), and outputs bias (1, -1, 0) for plug-and-play integration.
Export the regime bias for programmatic use.
As described above, use input.source() in your Pine Script strategy or system and link the bias output.
You can now filter signals, control trade direction/size, or design pairs-trading that respect true, indicator-driven market regimes.
With this framework, you’re not limited to static or simplistic regime filters. You can rigorously define, test, and refine what “market regime” means for your strategies—using the technical features that matter most to you.
Optimize your signal generation by backtesting across a universe of meaningful indicator blends.
Enhance risk management with objective, real-time regime boundaries.
Accelerate your research: iterate quickly, swap indicator components, and see results with minimal code changes.
Automate multi-asset or pairs-trading by integrating regime context directly into strategy logic.
Add both scripts to your chart, connect your preferred features, and start investigating your best regime-based trades—entirely within the TradingView ecosystem.
References & Further Reading
Ang, A., & Bekaert, G. (2002). “Regime Switches in Interest Rates.” Journal of Business & Economic Statistics, 20(2), 163–182.
Hamilton, J. D. (1989). “A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle.” Econometrica, 57(2), 357–384.
Markov, A. A. (1906). "Extension of the Limit Theorems of Probability Theory to a Sum of Variables Connected in a Chain." The Notes of the Imperial Academy of Sciences of St. Petersburg.
Guidolin, M., & Timmermann, A. (2007). “Asset Allocation under Multivariate Regime Switching.” Journal of Economic Dynamics and Control, 31(11), 3503–3544.
Murphy, J. J. (1999). Technical Analysis of the Financial Markets. New York Institute of Finance.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). “Simple Technical Trading Rules and the Stochastic Properties of Stock Returns.” Journal of Finance, 47(5), 1731–1764.
Zucchini, W., MacDonald, I. L., & Langrock, R. (2017). Hidden Markov Models for Time Series: An Introduction Using R (2nd ed.). Chapman and Hall/CRC.
On Quantitative Finance and Markov Models:
Lo, A. W., & Hasanhodzic, J. (2009). The Heretics of Finance: Conversations with Leading Practitioners of Technical Analysis. Bloomberg Press.
Patterson, S. (2016). The Man Who Solved the Market: How Jim Simons Launched the Quant Revolution. Penguin Press.
TradingView Pine Script Documentation: www.tradingview.com
TradingView Blog: “Use an Input From Another Indicator With Your Strategy” www.tradingview.com
GeeksforGeeks: “What is the Difference Between Markov Chains and Hidden Markov Models?” www.geeksforgeeks.org
What makes this indicator original and unique?
- On‑chart, real‑time Markov. The chain is drawn directly on your chart. You see the current regime, its tendency to stay (self‑loop), and the usual next step (arrows) as bars confirm.
- Source‑agnostic by design. The engine runs on any series you select via input.source() — price, your own oscillator, a composite score, anything you compute in the script.
- Automatic normalization + regime mapping. Different inputs live on different scales. The script standardizes your chosen source and maps it into clear regimes (e.g., Bull / Bear / Neutral) without you micromanaging thresholds each time.
- Rolling, bar‑by‑bar learning. Transition tendencies are computed from a rolling window of confirmed bars. What you see is exactly what the market did in that window.
- Fast experimentation. Switch the source, adjust the window, and the Markov view updates instantly. It’s a rapid way to test ideas and feel regime persistence/switch behavior.
Integrate your own signals (using input.source())
- In settings, choose the Source . This is powered by input.source() .
- Feed it price, an indicator you compute inside the script, or a custom composite series.
- The script will automatically normalize that series and process it through the Markov engine, mapping it to regimes and updating the on‑chart spheres/arrows in real time.
Credits:
Deep gratitude to @RicardoSantos for both the foundational Markov chain processing engine and inspiring open-source contributions, which made advanced probabilistic market modeling accessible to the TradingView community.
Special thanks to @Alien_Algorithms for the innovative and visually stunning 3D sphere logic that powers the indicator’s animated, regime-based visualization.
Disclaimer
This tool summarizes recent behavior. It is not financial advice and not a guarantee of future results.
INSTITUTIONAL GHOST [Jorge's Algo]Here is the professional English translation for your TradingView publication. It uses the correct technical terminology (SMC, ICT, Order Flow) to attract serious traders.
Title: INSTITUTIONAL GHOST
Subtitle: The Institutional Footprint Algorithm: Liquidity, Structure, and Volume (CVD).
DESCRIPTION:
INSTITUTIONAL GHOST is not just an indicator; it is a complete vision system engineered to clear market noise and reveal only what matters: Where is the liquidity, and when are institutions entering?
Unlike conventional indicators that clutter your chart with colors and false signals, the Ghost Protocol operates on absolute minimalism. It only displays information when high-probability algorithmic conditions are met, based on Smart Money Concepts (SMC) and Cumulative Volume Delta (CVD).
🔥 KEY FEATURES:
1. LIQUIDITY DETECTOR (Lr): The algorithm automatically identifies Major Swing Points where retail Stop Losses reside.
"Lr" Lines: Minimalist projections that act as magnets for price.
2. POWER SWEEPS (The Institutional Trap): Forget signal spam on every candle. This system filters noise and only marks a "Power Sweep" (Cyan Diamond) when:
Price sweeps a major liquidity level.
IMMEDIATE REJECTION: The candle closes in the opposite direction of the breakout (e.g., breaks high but closes bearish).
This confirms a Stop Hunt and rapid distribution.
3. CVD DIVERGENCE (The Lie Detector): In the background, the script calculates the Cumulative Volume Delta.
If a small "D" label appears above a Sweep, it means price made a New High/Low, but the Order Flow (real money) did not support it.
Signal: Confirmed Divergence = High probability reversal.
4. FVG GHOST LINES: Identification of Fair Value Gaps (Imbalances) without intrusive boxes. Only fine vertical lines connecting the gap, maintaining a "Clean Chart" aesthetic.
5. ICT MIDNIGHT OPEN: A discrete marker at the New York Open (00:00 NY) to determine the Daily Bias (Premium vs. Discount).
📋 HOW TO TRADE THIS ALGORITHM (THE MECHANICAL PLAN):
WAIT: Let price approach a Liquidity Line (Lr). Do not chase the price.
OBSERVE: Look for the appearance of the Cyan Diamond (Power Sweep). This indicates liquidity has been taken and rejected.
CONFIRM: If the "D" (Divergence) appears, the signal is "institutionally validated" by volume.
EXECUTE: Enter at the close of the Sweep candle or on the retest of the nearest FVG.
AUTHOR'S NOTE: This script was designed under the philosophy of "Less is More." If the chart is empty, it is because there is nothing to do. Patience pays.
Recommended Settings: M15, H1, H4 (Forex, Gold, Indices). Style: Minimalist / Zen.

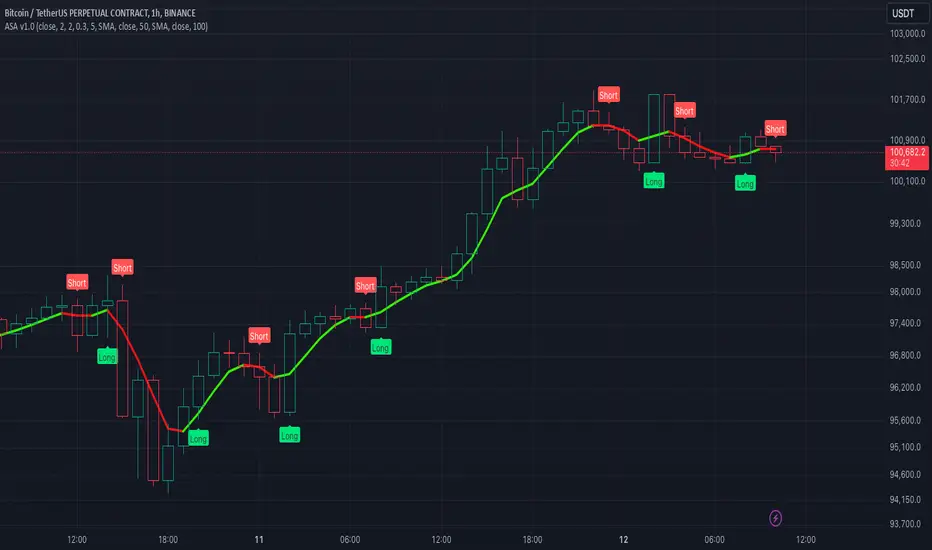
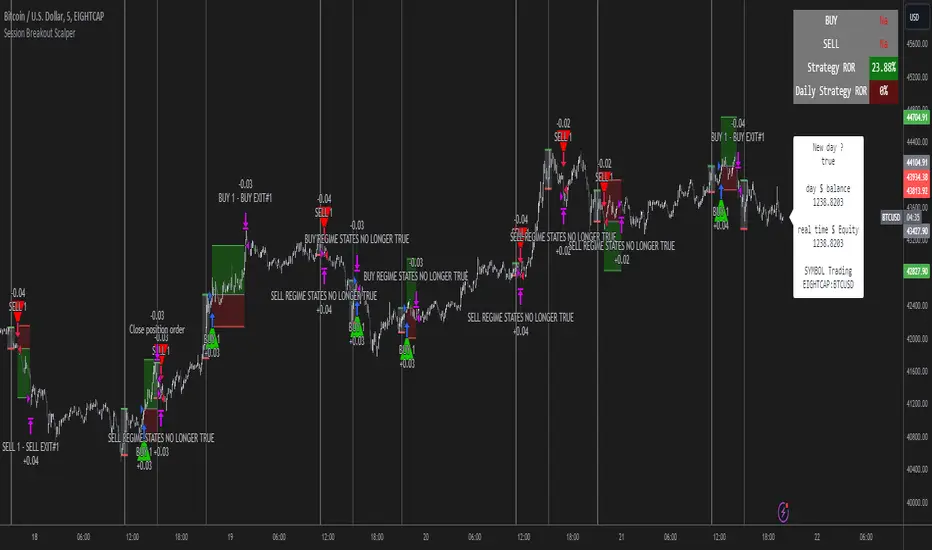
Session Breakout Scalper Trading BotHi Traders !
Introduction:
I have recently been exploring the world of automated algorithmic trading (as I prefer more objective trading strategies over subjective technical analysis (TA)) and would like to share one of my automation compatible (PineConnecter compatible) scripts “Session Breakout Scalper”.
The strategy is really simple and is based on time conditional breakouts although has more ”relatively” advanced optional features such as the regime indicators (Regime Filters) that attempt to filter out noise by adding more confluence states and the ATR multiple SL that takes into account volatility to mitigate the down side risk of the trade.
What is Algorthmic Trading:
Firstly what is algorithmic trading? Algorithmic trading also known as algo-trading, is a method of using computer programs (in this case pine script) to execute trades based on predetermined rules and instructions (this trading strategy). It's like having a robot trader who follows a strict set of commands to buy and sell assets automatically, without any human intervention.
Important Note:
For Algorithmic trading the strategy will require you having an essential TV subscription at the minimum (so that you can set alerts) plus a PineConnecter subscription (scroll down to the .”How does the strategy send signals” headings to read more)
The Strategy Explained:
Is the Time input true ? (this can be changed by toggling times under the “TRADE MEDIAN TIMES” group for user inputs).
Given the above is true the strategy waits x bars after the session and then calculates the highest high (HH) to lowest low (LL) range. For this box to form, the user defined amount of bars must print after the session. The box is symmetrical meaning the HH and LL are calculated over a lookback that is equal to the sum of user defined bars before and after the session (+ 1).
The Strategy then simultaneously defines the HH as the buy level (green line) and the LL as the sell level (red line). note the strategy will set stop orders at these levels respectively.
Enter a buy if price action crosses above the HH, and then cancel the sell order type (The opposite is true for a stop order).
If the momentum based regime filters are true the strategy will check for the regime / regimes to be true, if the regime if false the strategy will exit the current trade, as the regime filter has predicted a slowing / reversal of momentum.
The image below shows the strategy executing these trading rules ( Regime filters, "Trades on chart", "Signal & Label" and "Quantity" have been omitted. "Strategy label plots" has been switched to true)
Other Strategy Rules:
If a new session (time session which is user defined) is true (blue vertical line) and the strategy is currently still in a trade it will exit that trade immediately.
It is possible to also set a range of percentage gain per day that the strategy will try to acquire, if at any point the strategy’s profit is within the percentage range then the position / trade will be exited immediately (This can be changed in the “PERCENT DAY GAIN” group for user inputs)
Stops and Targets:
The strategy has either static (fixed) or variable SL options. TP however is only static. The “STRAT TP & TP” group of user inputs is responsible for the SL and TP values (quoted in pips). Note once the ATR stop is set to true the SL values in the above group no longer have any affect on the SL as expected.
What are the Regime Filters:
The Larry Williams Large Trade Index (LWLTI): The Larry Williams Large Trade Index (LWTI) is a momentum-based technical indicator developed by iconic trader Larry Williams. It identifies potential entries and exits for trades by gauging market sentiment, particularly the buying and selling pressure from large market players. Here's a breakdown of the LWTI:
LWLTI components and their interpretation:
Oscillator: It oscillates between 0 and 100, with 50 acting as the neutral line.
Sentiment Meter: Values above 75 suggest a bearish market dominated by large selling, while readings below 25 indicate a bullish market with strong buying from large players.
Trend Confirmation: Crossing above 75 during an uptrend and below 25 during a downtrend confirms the trend's continuation.
The Andean Oscillator (AO) : The Andean Oscillator is a trend and momentum based indicator designed to measure the degree of variations within individual uptrends and downtrends in the prices.
Regime Filter States:
In trading, a regime filter is a tool used to identify the current state or "regime" of the market.
These Regime filters are integrated within the trading strategy to attempt to lower risk (equity volatility and/or draw down). The regime filters have different states for each market order type (buy and sell). When the regime filters are set to true, if these regime states fail to be true the trade is exited immediately.
For Buy Trades:
LWLTI positive momentum state: Quotient of the lagged trailing difference and the ATR > 50
AO positive momentum state: Bull line > Bear line (signal line is omitted)
For Sell Trades:
LWLTI negative momentum stat: Quotient of the lagged trailing difference and the ATR < 50
AO negative momentum state: Bull line < Bear line (signal line is omitted)
How does the Strategy Send Signals:
The strategy triggers a TV alert (you will neet to set a alert first), TV then sends a HTTP request to the automation software (PineConnecter) which receives the request and then communicates to an MT4/5 EA to automate the trading strategy.
For the strategy to send signals you must have the following
At least a TV essential subscription
This Script added to your chart
A PineConnecter account, which is paid and not free. This will provide you with the expert advisor that executes trades based on these strategies signals.
For more detailed information on the automation process I would recommend you read the PineConnecter documentation and FAQ page.
Dashboard:
This Dashboard (top right by defualt) lists some simple trading statistics and also shows when a trade is live.
Important Notice:
- USE THIS STRATEGY AT YOUR OWN RISK AND ALWAYS DO YOUR OWN RESEARCH & MANUAL BACKTESTING !
- THE STRATEGY WILL NOT EXHIBIT THE BACKTEST PERFORMANCE SEEN BELOW IN ALL MARKETS !
ORB Algo | Flux Charts💎 GENERAL OVERVIEW
Introducing our new ORB Algo indicator! ORB stands for "Opening Range Breakout" which is a common trading strategy. The indicator can analyze the market trend in the current session and give "Buy / Sell", "Take Profit" and "Stop Loss" signals. For more information about the analyzing process of the indicator, you can read "How Does It Work ?" section of the description.
Features of the new ORB Algo indicator :
Buy & Sell Signals
Up To 3 Take Profit Signals
Stop-Loss Signals
Alerts for Buy / Sell, Take-Profit and Stop-Loss
Customizable Algoritm
Session Dashboard
Backtesting Dashboard
📌 HOW DOES IT WORK ?
This indicator works best in 1-minute timeframe. The idea is that the trend of the current session can be forecasted by analyzing the market for a while after the session starts. However, each market has it's own dynamics and the algorithm will need fine-tuning to get the best performance possible. So, we've implemented a "Backtesting Dashboard" that shows the past performance of the algorithm in the current ticker with your current settings. Always keep in mind that past performance does not guarantee future results.
Here are the steps of the algorithm explained briefly :
1. The algorithm follows and analyzes the first 30 minutes (can be adjusted) of the session.
2. Then, algorithm checks for breakouts of the opening range's high or low.
3. If a breakout happens in a bullish or a bearish direction, the algorithm will now check for retests of the breakout. Depending on the sensitivity setting, there must be 0 / 1 / 2 / 3 failed retests for the breakout to be considered as reliable.
4. If the breakout is reliable, the algorithm will give an entry signal.
5. After the position entry, algorithm will now wait for Take-Profit or Stop-Loss zones and signal if any of them occur.
If you wonder how does the indicator find Take-Profit & Stop-Loss zones, you can check the "Settings" section of the description.
🚩UNIQUENESS
While there are indicators that show the opening range of the session, they come short with features like indicating breakouts, entries, and Take-Profit & Stop-Loss zones. We are also aware of that different stock markets have different dynamics, and tuning the algorithm for different markets is really important for better results, so we decided to make the algorithm fully customizable. Besides all that, our indicator contains a detailed backtesting dashboard, so you can see past performance of the algorithm in the current ticker. While past performance does not yield any guarantee for future results, we believe that a backtesting dashboard is necessary for tuning the algorithm. Another strength of this indicator is that there are multiple options for detection of Take-Profit and Stop-Loss zones, which the trader can select one of their liking.
⚙️SETTINGS
Keep in mind that best chart timeframe for this indicator to work is the 1-minute timeframe.
TP = Take-Profit
SL = Stop-Loss
EMA = Exponential Moving Average
OR = Opening Range
ATR = Average True Range
1. Algorithm
ORB Timeframe -> This setting determines the timeframe that the algorithm will analyze the market after a new session begins before giving any signals. It's important to experiment with this setting and find the best option that suits the current ticker for the best performance. More volatile stocks will often require this setting to be larger, while more stabilized stocks may have this setting shorter.
Sensitivity -> This setting determines how much failed retests are needed to take a position entry. Higher senstivity means that less retests are needed to consider the breakout as reliable. If you think that the current ticker makes strong movements in a bullish & bearish direction after a breakout, you should set this setting higher. If you think the opposite, meaning that the ticker does not decide the trend right after a breakout, this setting show be lower.
(High = 0 Retests, Medium = 1 Retest, Low = 2 Retests, Lowest = 3 Retests)
Breakout Condition -> The condition for the algorithm to detect breakouts.
Close = Bar needs to close higher than the OR High Line in a bullish breakout, or lower than the OR Low Line in a bearish breakout. EMA = The EMA of the bar must be higher / lower than OR Lines instead of the close price.
TP Method -> The method for the algorithm to use when determining TP zones.
Dynamic = This TP method essentially tries to find the bar that price starts declining the current trend and going to the other direction, and puts a TP zone there. To achieve this, it uses an EMA line, and when the close price of a bar crosses the EMA line, It's a TP spot.
ATR = In this TP method, instead of a dynamic approach the TP zones are pre-determined using the ATR of the entry bar. This option is generally for traders who just want to know their TP spots beforehand while trading. Selecting this option will also show TP zones at the ORB Dashboard.
"Dynamic" option generally performs better, while the "ATR" method is safer to use.
EMA Length -> This setting determines the length of the EMA line used in "Dynamic TP method" and "EMA Breakout Condition". This is completely up to the trader's choice, though the default option should generally perform well. You might want to experiment with this setting and find the optimal length for the current ticker.
Stop-Loss -> Algorithm will place the Stop-Loss zone using setting.
Safer = The SL zone will be placed closer to the OR High for a bullish entry, and closer to the OR Low for a bearish entry.
Balanced = The SL zone will be placed in the center of OR High & OR Low
Risky = The SL zone will be placed closer to the OR Low for a bullish entry, and closer to the OR High for a bearish entry.
Adaptive SL -> This option only takes effect if the first TP zone is hit.
Enabled = After the 1st TP zone is hit, the SL zone will be moved to the entry price, essentially making the position risk-free.
Disabled = The SL zone will never change.
2. ORB Dashboard
ORB Dashboard shows the information about the current session.
3. ORB Backtesting
ORB Backtesting Dashboard allows you to see past performance of the algorithm in the current ticker with current settings.
Total amount of days that can be backtested depends on your TV subscription.
Backtesting Exit Ratios -> You can select how much of percent your entry will be closed at any TP zone while backtesting. For example, %90, %5, %5 means that %90 of the position will be closed at the first TP zone, %5 of it will be closed at the 2nd TP zone, and %5 of it will be closed at the last TP zone.

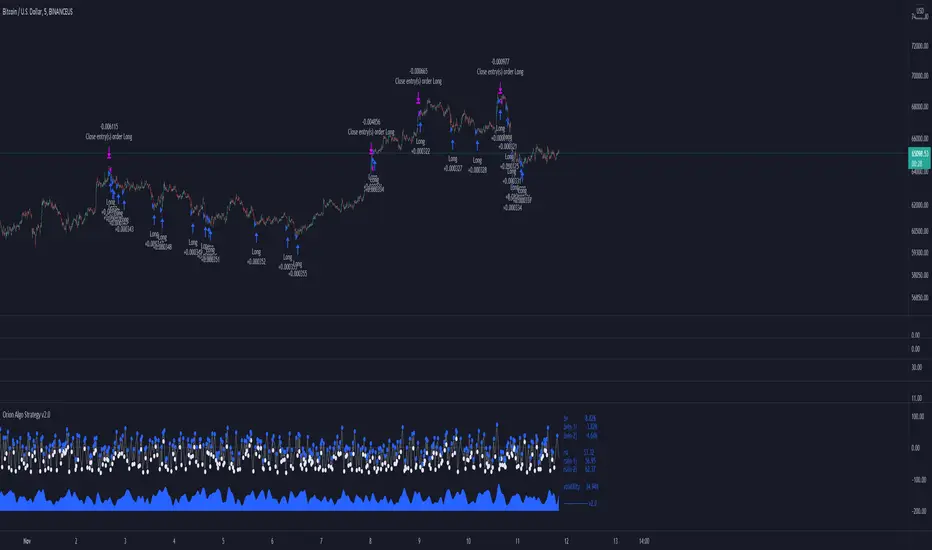
Orion Algo Strategy v2.0Hi everyone.
I decided to make the latest Orion Algo open to people. I don't have enough time to work on it lately, so I figured it would be best that everyone can have it to work on it. I took out some stuff from the original but it should give an idea on how things work. I made two strategies with this so far so you can use that to come up with your own. I recommend the DCA strategy because it gives you the most bang for Orion Algo's buck. It's pretty good at finding long entries.
Overall I hope you guys like this one. Also, Banano is the best crypto currency :)
-INFO-
Orion Algo is a trading algorithm designed to help traders find the highs and lows of the market before, during, and after they happen. We wanted to give an indicator to people that was simple to use. In fact we created the algorithm in such a way that it currently only needs a single input from the user. Since no indicator can predict the market perfectly, Orion should be used as just another tool (although quite a sharp one) for you to trade with. Fundamental knowledge of price action and TA should be used with Orion Algo.
Being an oscillator, Orion currently has a bias towards market volatility . So you will want to be trading markets over 30% volatility . We have plans to develop future versions that take this into account and adjust automatically for dead conditions. Also, while there are some similarities across all oscillators, what sets ours apart is the prediction curve. The prediction curve looks at the current signal values and gives it a relative score to approximate tops and bottoms 1-2 bars ahead of the signal curve. We also designed a velocity curve that attempts to predict the signal curve 2+ bars ahead. You can find the relative change in velocity in the Info panel. The bottom momentum wave is based on the signal curve and helps find overall market direction of higher time-frames while in a lower one.
Settings and How to Use them:
User Agreement – Orion Algo is a tool for you to use while trading. We aren’t responsible for losses OR the gains you make with it. By clicking the checkbox on the left you are agreeing to the terms.
Super Smooth – Smooths the main signal line based on the value inside the box. Lower values shift the pivot points to the left but also make things more noisy. Higher values move things to the right making it lag a bit more while creating a smoother signal. 8 is a good value to start with.
Theme – Changes the color scheme of Orion.
Dashboard – Turns on a dashboard with useful stats, such as Delta v, Volatility , Rsi , etc. Changing the value box will move the dashboard left and right.
Prediction – A secondary prediction model that attempts to predict a reversal before it happens (0-2bars). This can be noisy some times so make your best judgement. Curve will toggle a curve view of the prediction. Pivots will toggle bull/bear dots.
∆v – Delta v (change in velocity). This shows momentum of the signal. Crossing 0 signals a reversal. If you see the delta v changing direction, it may signify a reversal in the several bars depending on the overall momentum of the market.
Momentum Wave – Uses the signal as a macro trend indicator. Changes in direction of the wave can signify macro changes in the market. Average will toggle an averaging algorithm of the momentum waves and makes it easy to understand.
-STRATEGIES-
Simple - Just buy and sell on the dots
DCA - Uses the settings in the script for entries. If a buy dot appears then it will buy, if the price goes below the percentage it will wait for another dot before entering. This drastically improves DCA potential.
Order Blocks v2Order Blocks v2 – Smart OB Detection with Time & FVG Filters
Order Blocks v2 is an advanced tool designed to identify potential institutional footprints in the market by dynamically plotting bullish and bearish order blocks.
This indicator refines classic OB logic by combining:
Fractal-based break conditions
Time-level filtering (Power of 3)
Optional Fair Value Gap (FVG) confirmation
Real-time plotting and auto-invalidation
Perfect for traders using ICT, Smart Money, or algorithmic timing models like Hopplipka.
🧠 What the indicator does
Detects order blocks after break of bullish/bearish fractals
Supports 3-bar or 5-bar fractal structures
Allows OB detection based on close breaks or high/low breaks
Optionally confirms OBs only if followed by a Fair Value Gap within N candles
Filters OBs based on specific time levels (3, 7, 11, 14) — core anchors in many algorithmic models
Automatically deletes invalidated OBs once price closes through the zone
⚙️ How it works
The indicator:
Tracks local fractal highs/lows
Once a fractal is broken by price, it backtracks to identify the best OB candle (highest bullish or lowest bearish)
Validates the level by checking:
OB type logic (close or HL break)
Time stamp match with algorithmic time anchors (e.g. 3, 7, 11, 14 – known from the Power of 3 concept)
Optional FVG confirmation after OB
Plots OB zones as lines (body or wick-based) and removes them if invalidated by a candle close
This ensures traders see only valid, active levels — removing noise from broken or out-of-context zones.
🔧 Customization
Choose 3-bar or 5-bar fractals
OB detection type: close break or HL break
Enable/disable OBs only on times 3, 7, 11, 14 (Hopplipka style)
Optional: require nearby FVG for validation
Line style: solid, dashed, or dotted
Adjust OB length, width, color, and use body or wick for OB height
🚀 How to use it
Add the script to your chart
Choose your preferred OB detection mode and filters
Use plotted OB zones to:
Anticipate price rejections and reversals
Validate Smart Money or ICT-based entry zones
Align setups with algorithmic time sequences (3, 7, 11, 14)
Filter out invalid OBs automatically, keeping your chart clean
The tool is useful on any timeframe but performs best when combined with a liquidity-based or time-anchored trading model.
💡 What makes it original
Combines fractal logic with OB confirmation and time anchors
Implements time-based filtering inspired by Hopplipka’s interpretation of the "Power of 3"
Allows OB validation via optional FVG follow-up — rarely available in public indicators
Auto-cleans invalidated OBs to reduce clutter
Designed to reflect market structure logic used by institutions and algorithms
💬 Why it’s worth using
Order Blocks v2 simplifies one of the most nuanced parts of SMC: identifying clean and high-probability OBs.
It removes subjectivity, adds clear timing logic, and integrates optional confluence tools — like FVG.
For traders serious about algorithmic-level structure and clean setups, this tool delivers both logic and clarity.
⚠️ Important
This indicator:
Is not a signal generator or financial advice tool
Is intended for experienced traders using OB/SMC/time-based logic
Does not predict market direction — it provides visual structural levels only
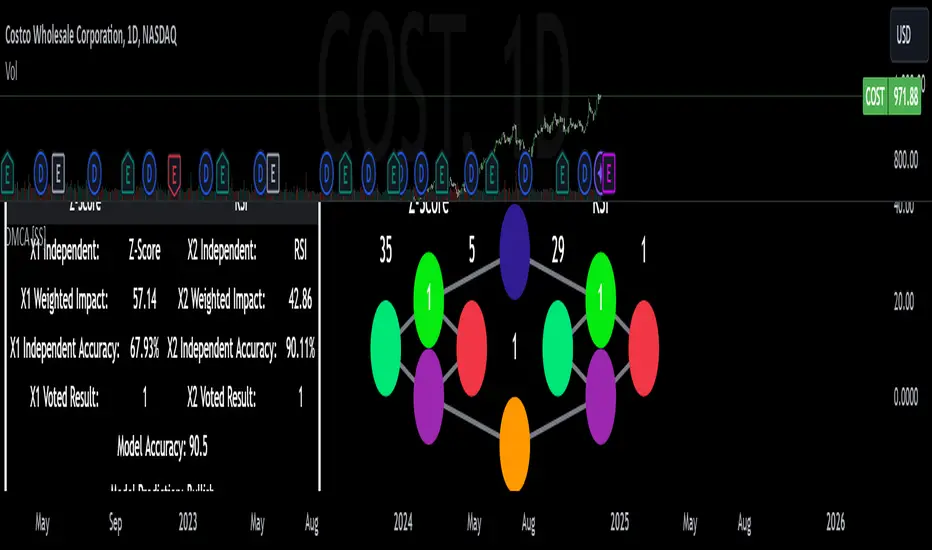
Simple Decesion Matrix Classification Algorithm [SS]Hello everyone,
It has been a while since I posted an indicator, so thought I would share this project I did for fun.
This indicator is an attempt to develop a pseudo Random Forest classification decision matrix model for Pinescript.
This is not a full, robust Random Forest model by any stretch of the imagination, but it is a good way to showcase how decision matrices can be applied to trading and within Pinescript.
As to not market this as something it is not, I am simply calling it the "Simple Decision Matrix Classification Algorithm". However, I have stolen most of the aspects of this machine learning algo from concepts of Random Forest modelling.
How it works:
With models like Support Vector Machines (SVM), Random Forest (RF) and Gradient Boosted Machine Learning (GBM), which are commonly used in Machine Learning Classification Tasks (MLCTs), this model operates similarity to the basic concepts shared amongst those modelling types. While it is not very similar to SVM, it is very similar to RF and GBM, in that it uses a "voting" system.
What do I mean by voting system?
How most classification MLAs work is by feeding an input dataset to an algorithm. The algorithm sorts this data, categorizes it, then introduces something called a confusion matrix (essentially sorting the data in no apparently order as to prevent over-fitting and introduce "confusion" to the algorithm to ensure that it is not just following a trend).
From there, the data is called upon based on current data inputs (so say we are using RSI and Z-Score, the current RSI and Z-Score is compared against other RSI's and Z-Scores that the model has saved). The model will process this information and each "tree" or "node" will vote. Then a cumulative overall vote is casted.
How does this MLA work?
This model accepts 2 independent variables. In order to keep things simple, this model was kept as a three node model. This means that there are 3 separate votes that go in to get the result. A vote is casted for each of the two independent variables and then a cumulative vote is casted for the overall verdict (the result of the model's prediction).
The model actually displays this system diagrammatically and it will likely be easier to understand if we look at the diagram to ground the example:
In the diagram, at the very top we have the classification variable that we are trying to predict. In this case, we are trying to predict whether there will be a breakout/breakdown outside of the normal ATR range (this is either yes or no question, hence a classification task).
So the question forms the basis of the input. The model will track at which points the ATR range is exceeded to the upside or downside, as well as the other variables that we wish to use to predict these exceedences. The ATR range forms the basis of all the data flowing into the model.
Then, at the second level, you will see we are using Z-Score and RSI to predict these breaks. The circle will change colour according to "feature importance". Feature importance basically just means that the indicator has a strong impact on the outcome. The stronger the importance, the more green it will be, the weaker, the more red it will be.
We can see both RSI and Z-Score are green and thus we can say they are strong options for predicting a breakout/breakdown.
So then we move down to the actual voting mechanisms. You will see the 2 pink boxes. These are the first lines of voting. What is happening here is the model is identifying the instances that are most similar and whether the classification task we have assigned (remember out ATR exceedance classifier) was either true or false based on RSI and Z-Score.
These are our 2 nodes. They both cast an individual vote. You will see in this case, both cast a vote of 1. The options are either 1 or 0. A vote of 1 means "Yes" or "Breakout likely".
However, this is not the only voting the model does. The model does one final vote based on the 2 votes. This is shown in the purple box. We can see the final vote and result at the end with the orange circle. It is 1 which means a range exceedance is anticipated and the most likely outcome.
The Data Table Component
The model has many moving parts. I have tried to represent the pivotal functions diagrammatically, but some other important aspects and background information must be obtained from the companion data table.
If we bring back our diagram from above:
We can see the data table to the left.
The data table contains 2 sections, one for each independent variable. In this case, our independent variables are RSI and Z-Score.
The data table will provide you with specifics about the independent variables, as well as about the model accuracy and outcome.
If we take a look at the first row, it simply indicates which independent variable it is looking at. If we go down to the next row where it reads "Weighted Impact", we can see a corresponding percent. The "weighted impact" is the amount of representation each independent variable has within the voting scheme. So in this case, we can see its pretty equal, 45% and 55%, This tells us that there is a slight higher representation of z-score than RSI but nothing to worry about.
If there was a major over-respresentation of greater than 30 or 40%, then the model would risk being skewed and voting too heavily in favour of 1 variable over the other.
If we move down from there we will see the next row reads "independent accuracy". The voting of each independent variable's accuracy is considered separately. This is one way we can determine feature importance, by seeing how well one feature augments the accuracy. In this case, we can see that RSI has the greatest importance, with an accuracy of around 87% at predicting breakouts. That makes sense as RSI is a momentum based oscillator.
Then if we move down one more, we will see what each independent feature (node) has voted for. In this case, both RSI and Z-Score voted for 1 (Breakout in our case).
You can weigh these in collaboration, but its always important to look at the final verdict of the model, which if we move down, we can see the "Model prediction" which is "Bullish".
If you are using the ATR breakout, the model cannot distinguish between "Bullish" or "Bearish", must that a "Breakout" is likely, either bearish or bullish. However, for the other classification tasks this model can do, the results are either Bullish or Bearish.
Using the Function:
Okay so now that all that technical stuff is out of the way, let's get into using the function. First of all this function innately provides you with 3 possible classification tasks. These include:
1. Predicting Red or Green Candle
2. Predicting Bullish / Bearish ATR
3. Predicting a Breakout from the ATR range
The possible independent variables include:
1. Stochastics,
2. MFI,
3. RSI,
4. Z-Score,
5. EMAs,
6. SMAs,
7. Volume
The model can only accept 2 independent variables, to operate within the computation time limits for pine execution.
Let's quickly go over what the numbers in the diagram mean:
The numbers being pointed at with the yellow arrows represent the cases the model is sorting and voting on. These are the most identical cases and are serving as the voting foundation for the model.
The numbers being pointed at with the pink candle is the voting results.
Extrapolating the functions (For Pine Developers:
So this is more of a feature application, so feel free to customize it to your liking and add additional inputs. But here are some key important considerations if you wish to apply this within your own code:
1. This is a BINARY classification task. The prediction must either be 0 or 1.
2. The function consists of 3 separate functions, the 2 first functions serve to build the confusion matrix and then the final "random_forest" function serves to perform the computations. You will need all 3 functions for implementation.
3. The model can only accept 2 independent variables.
I believe that is the function. Hopefully this wasn't too confusing, it is very statsy, but its a fun function for me! I use Random Forest excessively in R and always like to try to convert R things to Pinescript.
Hope you enjoy!
Safe trades everyone!
BTC and ETH Long strategy - version 1I will start with a small introduction about myself. I'm now trading cryto currencies manually for almost 2 years. I decided to start after watching a documentary on the TV showing people who made big money during the Bitcoin pump which happened at the end of 2017.
The next day, I asked myself "Why should I not give it a try and learn how to trade".
This was in February 2018 and the price of Bitcoin was around 11500USD.
I didn't know how to trade. In fact, I didn't know the trading industry at all.
So, my first step into trading was to open an account with a broken. Then I directly bought 200$ worst of BTC . At that time, I saw the graph and thought "This can only go back in the upward direction!" :)
I didn't know anything about Stop loss, Take profit and Risk management.
Today, almost 2 years after, I think that I know how to trade and can also confirm that I still hold this bag of 200$ of bitcoin from 2018 :)
I did spend the 2 last years to learn technical analysis , risk management and leverage trading.
Today (14/05/2020), I know what I'm doing and I'm happy to see that the 2 last years have been positive in terms of gains. Of course, I did not make crazy money with my saving but at least I made more than if I would have kept it in my bank account.
Even if I like trading, I have a full time job which requires my full energy and lots of focus, so, the biggest problem I had is that I didn't have enough time to look at the charts.
Also, I realized that sometimes, neither technical analysis , nor fundamentals worked with crypto currency (at least for short time trading). So, as I have a developer background I decided to try to have a look at algo trading.
The goal for me was neither to make complex algos nor to beat the market but just to automate my trading with simple bot catching the big waves.
I then started to take a look at TV pine script and played with it.
I did my first LONG script in February 2020 to Long the BTC Market. It has some limitations but works well enough for me for the time being. Even if the real trades will bring me half of what the back testing shows, this will still be a lot more than what I was used to win during the last 2 years with my manual trading.
So, here we are! Below you will find some details about my first LONG script. I'm happy to share it with you.
Feel free to play with it, give your comments and bring improvements to it.
But please note that it only works fine with the candle size and crypto pair that I have mentioned below. If you use other settings this algo might loose money!
- Crypto pairs : XBTUSD and ETHXBT
- Candle size: 2 Hours
- Indicator used: Volatility , MACD (12, 26, 7), SMA (100), SMA (200), EMA (20)
- Default StopLoss: -1.5%
- Entry in position if: Volatility < 2%
AND MACD moving up
AND AME (20) moving up
AND SMA (100) moving up
AND SMA (200) moving up
AND EMA (20) > SAM (100)
AND SMA (100) > SMA (200)
- Exit the postion if: Stoploss is reached
OR EMA (20) crossUnder SMA (100)
Here is a summary of the results for this script:
XBTUSD : 01/01/2019 --> 14/05/2020 = +107%
ETHXBT : 01/01/2019 --> 14/05/2020 = +39%
ETHUSD : 01/01/2019 --> 14/05/2020 = +112%
It is far away from being perfect. There are still plenty of things which can be done to improve it but I just wanted to share it :) .
Enjoy playing with it....

Long/Short Volatility AlgoA modification of my leveraged ETF algorithm. Giving out for free because it's a sloppy algorithm, and I personally use a much more refined algorithm developed by someone much smarter than me.
BE-QuantFlow: Adaptive Momentum Trading█ Overview: QuantFlow: Adaptive Momentum Trading
QuantFlow is a sophisticated algorithmic momentum trading method designed specifically for indices and high-beta stocks. However, its logic is universal; with appropriate parameter tuning, it adapts to various asset classes and timeframes.
While the standard momentum indicators (like RSI or MACD) simply measure how fast price is moving (Velocity), QuantFlow analyzes the quality and conviction of the trend . Features like Dynamic Volatility Filtering and Trend Shielding, combined with volatility weighting and a "Dual-Line" approach to distinguish between a sustainable institutional trend and a temporary retail spike, make the indicator unique and more powerful.
█ Why QuantFlow ?
Quant (The Engine): This replaces subjective guessing with objective math.
Instead of just seeing that the price is "up," we measure "how it got there". For example, a stock that rises 1 currency value every day for 10 days (smooth trend) gets a much higher score than a stock that jumps 10 currency value in one minute and does nothing else (erratic noise). This mathematical rigor provides the structure.
█ Core Logic & Philosophy
To understand how QuantFlow calculates momentum, imagine a "Tug-of-War" between Buyers (Bulls) and Sellers (Bears). Most indicators (like RSI) use a single line. If RSI is at 50, it means "Neutral." But "Neutral" can mean two very different things:
Peace: Nothing is happening. No one is buying or selling.
War: Buyers are pushing hard, but Sellers are pushing back equally hard. Volatility is massive.
A single line hides this reality. QuantFlow splits the market into two separate scores:
Bull Score (Green Line): How hard are the buyers pushing?
Bear Score (Red Line): How hard are the sellers pushing?
The Layman's Advantage:
If both lines are low = Sleepy Market (Avoid).
If Green is high and Red is low = Clean Uptrend (Buy).
If Red is high and Green is low = Clean Downtrend (Sell).
If both lines are high = Chaos/War Zone (Wait).
█ How it Weight "Sustenance" (The Critical Quality Check)
This is the most unique aspect of QuantFlow: Trend direction alone is not enough; Sustenance is weighed equally . Standard indicators treat every 10 currency value movements the same way with no distinction. However, QuantFlow asks, "Did you hold the ground you gained?"
Scenario A (High Sustenance) : A stock opens at 100, marches to 110, and closes at 110.
Verdict : Buyers pushed up and sustained the price.
QuantFlow Weight : 100%. This is a high-quality move.
Scenario B (Low Sustenance) : A stock opens at 100, spikes to 110, but gets sold off to close at 102.
Verdict : Buyers pushed up (Trend is Up), but failed to sustain it (Long Wick).
QuantFlow Weight : 20%. This is treated as "Noise" or a trap.
By mathematically weighing the Close Location Value (where the candle closes relative to its high/low), QuantFlow filters out "Gap-and-Fade" traps and exhaustion spikes that fool traditional indicators.
Comparisons: QuantFlow vs. The Rest
Calculation Logic : Standard RSI/MACD measures simple price change over time. QuantFlow measures Price Change 'times (x)' Conviction (Sustenance Weighting).
Visual Output : Standard tools show a single line (0-100), often hiding market conflict. QuantFlow displays Dual Lines (Bull vs Bear Intensity) to reveal the true state of the battle.
Trap Handling : Standard indicators are often fooled by sharp spikes. QuantFlow ignores "Gap-and-Fade" moves with poor closing conviction.
Adaptability : Standard tools use static levels (e.g., Overbought > 70). QuantFlow uses Dynamic Bands that adjust automatically to recent volatility.
█ Dynamic Volatility Filtering
Unlike standard indicators that use fixed levels (e.g., "Buy if RSI > 50"), QuantFlow acknowledges that "50" means something different in a quiet market versus a crashing market. This section explains the statistical engine driving the signals.
The Problem with Static Levels : In a low-volatility environment, a momentum score of 55 might indicate a massive breakout. In a high-volatility environment, a score of 55 might just be random noise. A fixed threshold cannot handle both scenarios.
The Solution: Adaptive Statistics : The script maintains a memory of the Momentum Events. It doesn't just look at price; it looks at where the momentum occurred in the past and draws a "Noise Zone" (Grey Band). This logic acts as a "Smart Gatekeeper" for trade entries:
Scenario A: Inside the Noise (The Filter)
If a new momentum signal happens inside the Noise Zone, the script assumes it is likely chop or noise.
Action : It forces a wait period. The signal is delayed until the trend sustains itself for Confirm Bars; else the signal is cancelled. This filters out ~70% of false signals in sideways markets.
Scenario B: Outside the Noise (The Breakout)
If a new momentum signal happens outside the Noise Zone (or the momentum score smashes through the Upper Band), it is statistically significant (an outlier event).
Action: It triggers an Immediate Entry. No waiting is required because the move is powerful enough to escape the historical noise zone.
█ The ⚠️ "Warning" System (Heads-up for Smart Reversals)
While you are directional if there is potential reversal signal, it provides the heads-up warning for a better decision-making
█ Special Utility: Ghost Mode
For intraday traders, the biggest disruption to "Flow" is the mandatory broker square-off at 3:15 PM (considering Indian Market). Often, a trend continues overnight, and the trader misses the gap-up opening the next morning because their algo was flat.
Ghost Mode is a unique feature that runs silently in the background:
At Square-off: The strategy closes your official position to satisfy the broker.
In the Background: It keeps the trade "alive" virtually (Ghost).
Next Morning: If the market opens in the trend's favor, the strategy re-enters the trade automatically. This approach ensures you capture the full swing of the trend, even if you are forced to exit at the previous session.
█ Advice on this indicator:
Parameter Calibration: The default settings are optimized for BankNifty on 5-minute charts. If you trade stocks, crypto, commodities, or any higher timeframes (e.g., 15-min or hourly), you must adjust these.
Low Volatility Assets: Reduce Stop Multiplier to 2.0.
High Volatility Assets: Increase Momentum Lookback to 50 to filter noise.
Confluence (Additional Confirmation): While QuantFlow is a complete system, using it alongside Key Support/Resistance Levels or Volume Profile provides the highest probability setups.

Adaptive Bull Ratio Strategy█ Overview: Why This Strategy
Most option strategies fall into two traps:
They are too rigid: A "Call Ratio Spread" works great in slow markets but gets destroyed if the market rallies hard.
They are too simple: A simple "Buy Call" suffers from time decay (Theta) if the market chops sideways.
The Adaptive Bull Ratio Strategy solves both . It is a living strategy that "shifts gears" based on price action.
It is called "Adaptive" because it morphs its structure three times during a trade. It starts conservative to harvest Time Decay, but if the market explodes upwards, it "uncaps" itself to ride the trend aggressively.
█ The Entry Philosophy: Why Supertrend?
The default setting uses the Supertrend indicator as the trigger. This is intentional:
Volatility Awareness: Supertrend adapts to market noise using ATR. In high volatility, bands widen to prevent false entries.
Trend Confirmation: Since Phase 1 involves selling options, entering "too early" against a falling market is dangerous. Supertrend forces patience, waiting for a confirmed reversal (Close > Trend Line), ensuring the momentum is actually in your favor before you commit capital.
The "Drift" Benefit: This strategy excels in markets that "drift" upwards. Supertrend identifies these trends while filtering out short-term chop.
Flexibility with External Sources:
While Supertrend is the default, the strategy is designed to be flexible. You can enable the 'Enable External Source' option in the settings to plug in any custom indicator (e.g., Moving Averages, Parabolic SAR, or a proprietary trendline).
The Golden Rule for External Sources: The script interprets a Bullish Signal whenever your External Source line is below the Close price (Ext Source < Close).
Compatibility: As long as your custom indicator behaves like a support line in an uptrend (plotting below the candles), it will work seamlessly with this strategy's logic.
█ The "Long Only" Rationale: Avoiding the Volatility Trap
Why not trade this on the short side (Puts) during crashes?
The Volatility Trap (Vega Risk): In Bull markets, Implied Volatility (IV) usually drops, helping your sold options decay faster. In Bear markets, IV explodes (panic). Selling OTM Puts during a crash is dangerous as their value skyrockets, neutralizing gains.
Velocity Risk: Bear markets crash fast ("Elevator Down"). Prices can blow through adjustment levels faster than the strategy can safely roll down, causing slippage.
Structural Skew: OTM Puts are inherently more expensive. Buying expensive ITM Puts and selling expensive OTM Puts shifts the breakeven further away, making V-shape recoveries painful.
█ How It Works & Stands Out
This strategy actively transforms risk profiles based on market movement:
Phase 1: The "Safe" Start (Entry)
Setup: Initiates a Call Ratio Spread (Buy 2 ITM, Sell 4 OTM) + Protective Puts.
Logic: Profits from sideways drift or slow rallies via Time Decay (Theta). The sold options finance the trade.
Phase 2: The "Shift" (Adjustment Level 1)
Trigger: Market moves above Leg 2 (3 OTM Call).
Action: Rolls Up the position. Exits initial legs, enters new higher legs, and adds a Short Put to finance the roll.
Impact: Aggressive. You bet the trend is strong enough to support the added downside risk of the short put.
Phase 3: The "Uncap" (Adjustment Level 2)
Trigger: Market moves above Leg 3 (4 OTM Call).
Action: Exits all Sold Calls.
Impact: Uncaps profit potential. The trade becomes a Net Long position (Long Calls + Short Puts), allowing you to ride a massive rally without a ceiling.
Phase 4: The "Lock-In" (Optional Trail Adjustment)
Trigger: The market goes parabolic (price rises X levels above Leg 3, configurable in settings).
Action (If Enabled):
Call Adj: Exits the Phase 3 calls and buys fresh 1-OTM calls (Rolling Up to lock profits).
Put Adj: Exits all Put legs (Removing downside risk completely).
Impact: Maximum Safety. This phase is about "banking" the windfall from a massive rally and leaving a smaller, risk-free runner to capture any final extension.
█ How to Start: A Quick Setup Guide
Step 1: Map Expiry Dates
Manually input your trading expiry dates in Settings -> Expiry Management.
Format: YYYY-MM-DD (e.g., 2025-12-25). Strict adherence required for DhanHQ.
Step 2: Configure Symbol & Size
Exchange/Symbol: Enter NSE and NIFTY (or your ticker).
Lot Multiplier: Default is 1. Set to 2 to double all quantities (e.g., Buy 2 becomes Buy 4).
Step 3: Understand Visuals
Entry Window (Light Blue): Strategy is scanning for new trades.
Non-Entry Window (Dark Blue): Trading blocked (Day before Expiry & Expiry Day). Only management allowed.
Green Box: Valid Late Entry Zone.
Red Dashed Line: Invalidation Level (if price touches this, no late entry).
Fuchsia Line: Trigger level for Special Trail Adjustments (Phase 4).
IMPORTANT: Broker & Technology Heads-Up:
The alerts generated by this script ({"secret": "...", "alertType": "multi_leg_order"...}) are specifically formatted for the DhanHQ webhook structure.
Dhan Users: Plug-and-play.
Other Brokers: You need middleware (NextLevelBot, Quantiply) to parse the JSON.
█ Risk Disclaimer & Advice
Trading options involves substantial risk.
The Whipsaw Risk: In Phase 2, you are Long Calls and Short Puts. A sharp reversal causes losses on both sides.
Margin: Selling options requires significant margin. Keep a 15-20% cash buffer to handle adjustments instantly.
Testing: This strategy is optimized for NIFTY Weekly Options. Effectiveness on BankNifty or Stocks is untested and may require parameter tuning.
Advice:
Backtest: Use TradingView Replay.
Paper Trade: Run for at least one expiry cycle before live deployment.
Consult: Seek professional financial advice before trading.
Practical Tips for Smooth Execution
For a new trader deploying this system, these operational tips are vital:
Capital Buffer: Do not trade at your limit. Always keep 10-15% free cash in your broker account. Adjustments (specifically Phase 2, where you sell an extra Put) require additional margin instantly. If margin is short, the order fails, and your hedge breaks.
Liquidity Awareness : The script trades "Far Deep OTM" options (Leg 4) to reduce margin. On indices like Nifty/BankNifty, this is fine. On individual stocks, these deep strikes might be illiquid. Check the option chain volume before deploying on stocks.
Trust the Process (but Verify) : While the algo drives, you are the pilot.
Check your API connection every morning.
Ensure the "Entry Window" background color on the chart matches your real-world date.
Verify that your broker executed all legs of a multi-leg order (partial fills are rare but possible).
The "Human" Stop: If major news breaks (e.g., unexpected election results, war announcements), volatility can expand faster than any algo can react. It is acceptable—and smart—to pause the strategy during known "Black Swan" events or earnings releases.
█ Timeframe Selection: The 30-Minute Standard
Critical Requirement: This indicator must be applied to a 30-minute chart.
Why?
Noise Filtering: The Supertrend logic is tuned to capture multi-day trends. Lower timeframes (5m, 15m) are full of "noise"—random fluctuations that look like trend changes but aren't.
Execution Logic (The Hybrid Engine): The script has a built-in "Dual Timeframe" architecture.
Decision Layer (30m): Uses the chart timeframe to decide when to be Bullish or Bearish.
Execution Layer (5m): Internally fetches 5-minute data to manage the how (Adjustments, Late Entries, and precise invalidation).
The Risk of Lower Timeframes: If you run the main chart on 5-minutes, you destroy this hierarchy. You will get too many signals, pay too much brokerage, and the internal logic may behave erratically.
Recommendation: Always keep your TradingView chart interval at 30m. Do not switch to lower timeframes expecting "faster" signals; you will likely just get "false" signals.
█ Testing Scope, Feedback
⚠️ Important Note on Asset Classes:
This strategy logic and the associated strike step calculations have been rigorously tested ONLY on NIFTY Index Options with Weekly Expiry.
BankNifty / Sensex / FinNifty: The volatility characteristics (ATR) and strike intervals of these instruments differ significantly from NIFTY. The effectiveness of this strategy on these other scripts has not been verified and may require different parameter tuning (e.g., strike_step or ATR Length).
Stocks: Individual stock options often lack the liquidity required for the "Deep OTM" legs, leading to potential execution failures.
We encourage traders to backtest this logic on other indices and share their findings! If you find a robust parameter set for BankNifty or observe unique behaviors on other scripts, please let us know in the comments below so we can improve the algorithm for everyone. Your feedback is appriciated.

PnL Bubble [%] | Fractalyst1. What's the indicator purpose?
The PnL Bubble indicator transforms your strategy's trade PnL percentages into an interactive bubble chart with professional-grade statistics and performance analytics. It helps traders quickly assess system profitability, understand win/loss distribution patterns, identify outliers, and make data-driven strategy improvements.
How does it work?
Think of this indicator as a visual report card for your trading performance. Here's what it does:
What You See
Colorful Bubbles: Each bubble represents one of your trades
Blue/Cyan bubbles = Winning trades (you made money)
Red bubbles = Losing trades (you lost money)
Bigger bubbles = Bigger wins or losses
Smaller bubbles = Smaller wins or losses
How It Organizes Your Trades:
Like a Photo Album: Instead of showing all your trades at once (which would be messy), it shows them in "pages" of 500 trades each:
Page 1: Your first 500 trades
Page 2: Trades 501-1000
Page 3: Trades 1001-1500, etc.
What the Numbers Tell You:
Average Win: How much money you typically make on winning trades
Average Loss: How much money you typically lose on losing trades
Expected Value (EV): Whether your trading system makes money over time
Positive EV = Your system is profitable long-term
Negative EV = Your system loses money long-term
Payoff Ratio (R): How your average win compares to your average loss
R > 1 = Your wins are bigger than your losses
R < 1 = Your losses are bigger than your wins
Why This Matters:
At a Glance: You can instantly see if you're a profitable trader or not
Pattern Recognition: Spot if you have more big wins than big losses
Performance Tracking: Watch how your trading improves over time
Realistic Expectations: Understand what "average" performance looks like for your system
The Cool Visual Effects:
Animation: The bubbles glow and shimmer to make the chart more engaging
Highlighting: Your biggest wins and losses get extra attention with special effects
Tooltips: hover any bubble to see details about that specific trade.
What are the underlying calculations?
The indicator processes trade PnL data using a dual-matrix architecture for optimal performance:
Dual-Matrix System:
• Display Matrix (display_matrix): Bounded to 500 trades for rendering performance
• Statistics Matrix (stats_matrix): Unbounded storage for complete statistical accuracy
Trade Classification & Aggregation:
// Separate wins, losses, and break-even trades
if val > 0.0
pos_sum += val // Sum winning trades
pos_count += 1 // Count winning trades
else if val < 0.0
neg_sum += val // Sum losing trades
neg_count += 1 // Count losing trades
else
zero_count += 1 // Count break-even trades
Statistical Averages:
avg_win = pos_count > 0 ? pos_sum / pos_count : na
avg_loss = neg_count > 0 ? math.abs(neg_sum) / neg_count : na
Win/Loss Rates:
total_obs = pos_count + neg_count + zero_count
win_rate = pos_count / total_obs
loss_rate = neg_count / total_obs
Expected Value (EV):
ev_value = (avg_win × win_rate) - (avg_loss × loss_rate)
Payoff Ratio (R):
R = avg_win ÷ |avg_loss|
Contribution Analysis:
ev_pos_contrib = avg_win × win_rate // Positive EV contribution
ev_neg_contrib = avg_loss × loss_rate // Negative EV contribution
How to integrate with any trading strategy?
Equity Change Tracking Method:
//@version=6
strategy("Your Strategy with Equity Change Export", overlay=true)
float prev_trade_equity = na
float equity_change_pct = na
if barstate.isconfirmed and na(prev_trade_equity)
prev_trade_equity := strategy.equity
trade_just_closed = strategy.closedtrades != strategy.closedtrades
if trade_just_closed and not na(prev_trade_equity)
current_equity = strategy.equity
equity_change_pct := ((current_equity - prev_trade_equity) / prev_trade_equity) * 100
prev_trade_equity := current_equity
else
equity_change_pct := na
plot(equity_change_pct, "Equity Change %", display=display.data_window)
Integration Steps:
1. Add equity tracking code to your strategy
2. Load both strategy and PnL Bubble indicator on the same chart
3. In bubble indicator settings, select your strategy's equity tracking output as data source
4. Configure visualization preferences (colors, effects, page navigation)
How does the pagination system work?
The indicator uses an intelligent pagination system to handle large trade datasets efficiently:
Page Organization:
• Page 1: Trades 1-500 (most recent)
• Page 2: Trades 501-1000
• Page 3: Trades 1001-1500
• Page N: Trades to
Example: With 1,500 trades total (3 pages available):
• User selects Page 1: Shows trades 1-500
• User selects Page 4: Automatically falls back to Page 3 (trades 1001-1500)
5. Understanding the Visual Elements
Bubble Visualization:
• Color Coding: Cyan/blue gradients for wins, red gradients for losses
• Size Mapping: Bubble size proportional to trade magnitude (larger = bigger P&L)
• Priority Rendering: Largest trades displayed first to ensure visibility
• Gradient Effects: Color intensity increases with trade magnitude within each category
Interactive Tooltips:
Each bubble displays quantitative trade information:
tooltip_text = outcome + " | PnL: " + pnl_str +
"\nDate: " + date_str + " " + time_str +
"\nTrade #" + str.tostring(trade_number) + " (Page " + str.tostring(active_page) + ")" +
"\nRank: " + str.tostring(rank) + " of " + str.tostring(n_display_rows) +
"\nPercentile: " + str.tostring(percentile, "#.#") + "%" +
"\nMagnitude: " + str.tostring(magnitude_pct, "#.#") + "%"
Example Tooltip:
Win | PnL: +2.45%
Date: 2024.03.15 14:30
Trade #1,247 (Page 3)
Rank: 5 of 347
Percentile: 98.6%
Magnitude: 85.2%
Reference Lines & Statistics:
• Average Win Line: Horizontal reference showing typical winning trade size
• Average Loss Line: Horizontal reference showing typical losing trade size
• Zero Line: Threshold separating wins from losses
• Statistical Labels: EV, R-Ratio, and contribution analysis displayed on chart
What do the statistical metrics mean?
Expected Value (EV):
Represents the mathematical expectation per trade in percentage terms
EV = (Average Win × Win Rate) - (Average Loss × Loss Rate)
Interpretation:
• EV > 0: Profitable system with positive mathematical expectation
• EV = 0: Break-even system, profitability depends on execution
• EV < 0: Unprofitable system with negative mathematical expectation
Example: EV = +0.34% means you expect +0.34% profit per trade on average
Payoff Ratio (R):
Quantifies the risk-reward relationship of your trading system
R = Average Win ÷ |Average Loss|
Interpretation:
• R > 1.0: Wins are larger than losses on average (favorable risk-reward)
• R = 1.0: Wins and losses are equal in magnitude
• R < 1.0: Losses are larger than wins on average (unfavorable risk-reward)
Example: R = 1.5 means your average win is 50% larger than your average loss
Contribution Analysis (Σ):
Breaks down the components of expected value
Positive Contribution (Σ+) = Average Win × Win Rate
Negative Contribution (Σ-) = Average Loss × Loss Rate
Purpose:
• Shows how much wins contribute to overall expectancy
• Shows how much losses detract from overall expectancy
• Net EV = Σ+ - Σ- (Expected Value per trade)
Example: Σ+: 1.23% means wins contribute +1.23% to expectancy
Example: Σ-: -0.89% means losses drag expectancy by -0.89%
Win/Loss Rates:
Win Rate = Count(Wins) ÷ Total Trades
Loss Rate = Count(Losses) ÷ Total Trades
Shows the probability of winning vs losing trades
Higher win rates don't guarantee profitability if average losses exceed average wins
7. Demo Mode & Synthetic Data Generation
When using built-in sources (close, open, etc.), the indicator generates realistic demo trades for testing:
if isBuiltInSource(source_data)
// Generate random trade outcomes with realistic distribution
u_sign = prand(float(time), float(bar_index))
if u_sign < 0.5
v_push := -1.0 // Loss trade
else
// Skewed distribution favoring smaller wins (realistic)
u_mag = prand(float(time) + 9876.543, float(bar_index) + 321.0)
k = 8.0 // Skewness factor
t = math.pow(u_mag, k)
v_push := 2.5 + t * 8.0 // Win trade
Demo Characteristics:
• Realistic win/loss distribution mimicking actual trading patterns
• Skewed distribution favoring smaller wins over large wins
• Deterministic randomness for consistent demo results
• Includes jitter effects to prevent visual overlap
8. Performance Limitations & Optimizations
Display Constraints:
points_count = 500 // Maximum 500 dots per page for optimal performance
Pine Script v6 Limits:
• Label Count: Maximum 500 labels per indicator
• Line Count: Maximum 100 lines per indicator
• Box Count: Maximum 50 boxes per indicator
• Matrix Size: Efficient memory management with dual-matrix system
Optimization Strategies:
• Pagination System: Handle unlimited trades through 500-trade pages
• Priority Rendering: Largest trades displayed first for maximum visibility
• Dual-Matrix Architecture: Separate display (bounded) from statistics (unbounded)
• Smart Fallback: Automatic page clamping prevents empty displays
Impact & Workarounds:
• Visual Limitation: Only 500 trades visible per page
• Statistical Accuracy: Complete dataset used for all calculations
• Navigation: Use page input to browse through entire trade history
• Performance: Smooth operation even with thousands of trades
9. Statistical Accuracy Guarantees
Data Integrity:
• Complete Dataset: Statistics matrix stores ALL trades without limit
• Proper Aggregation: Separate tracking of wins, losses, and break-even trades
• Mathematical Precision: Pine Script v6's enhanced floating-point calculations
• Dual-Matrix System: Display limitations don't affect statistical accuracy
Calculation Validation:
// Verified formulas match standard trading mathematics
avg_win = pos_sum / pos_count // Standard average calculation
win_rate = pos_count / total_obs // Standard probability calculation
ev_value = (avg_win * win_rate) - (avg_loss * loss_rate) // Standard EV formula
Accuracy Features:
• Mathematical Correctness: Formulas follow established trading statistics
• Data Preservation: Complete dataset maintained for all calculations
• Precision Handling: Proper rounding and boundary condition management
• Real-Time Updates: Statistics recalculated on every new trade
10. Advanced Technical Features
Real-Time Animation Engine:
// Shimmer effects with sine wave modulation
offset = math.sin(shimmer_t + phase) * amp
// Dynamic transparency with organic flicker
new_transp = math.min(flicker_limit, math.max(-flicker_limit, cur_transp + dir * flicker_step))
• Sine Wave Shimmer: Dynamic glowing effects on bubbles
• Organic Flicker: Random transparency variations for natural feel
• Extreme Value Highlighting: Special visual treatment for outliers
• Smooth Animations: Tick-based updates for fluid motion
Magnitude-Based Priority Rendering:
// Sort trades by magnitude for optimal visual hierarchy
sort_indices_by_magnitude(values_mat)
• Largest First: Most important trades always visible
• Intelligent Sorting: Custom bubble sort algorithm for trade prioritization
• Performance Optimized: Efficient sorting for real-time updates
• Visual Hierarchy: Ensures critical trades never get hidden
Professional Tooltip System:
• Quantitative Data: Pure numerical information without interpretative language
• Contextual Ranking: Shows trade position within page dataset
• Percentile Analysis: Performance ranking as percentage
• Magnitude Scaling: Relative size compared to page maximum
• Professional Format: Clean, data-focused presentation
11. Quick Start Guide
Step 1: Add Indicator
• Search for "PnL Bubble | Fractalyst" in TradingView indicators
• Add to your chart (works on any timeframe)
Step 2: Configure Data Source
• Demo Mode: Leave source as "close" to see synthetic trading data
• Strategy Mode: Select your strategy's PnL% output as data source
Step 3: Customize Visualization
• Colors: Set positive (cyan), negative (red), and neutral colors
• Page Navigation: Use "Trade Page" input to browse trade history
• Visual Effects: Built-in shimmer and animation effects are enabled by default
Step 4: Analyze Performance
• Study bubble patterns for win/loss distribution
• Review statistical metrics: EV, R-Ratio, Win Rate
• Use tooltips for detailed trade analysis
• Navigate pages to explore full trade history
Step 5: Optimize Strategy
• Identify outlier trades (largest bubbles)
• Analyze risk-reward profile through R-Ratio
• Monitor Expected Value for system profitability
• Use contribution analysis to understand win/loss impact
12. Why Choose PnL Bubble Indicator?
Unique Advantages:
• Advanced Pagination: Handle unlimited trades with smart fallback system
• Dual-Matrix Architecture: Perfect balance of performance and accuracy
• Professional Statistics: Institution-grade metrics with complete data integrity
• Real-Time Animation: Dynamic visual effects for engaging analysis
• Quantitative Tooltips: Pure numerical data without subjective interpretations
• Priority Rendering: Intelligent magnitude-based display ensures critical trades are always visible
Technical Excellence:
• Built with Pine Script v6 for maximum performance and modern features
• Optimized algorithms for smooth operation with large datasets
• Complete statistical accuracy despite display optimizations
• Professional-grade calculations matching institutional trading analytics
Practical Benefits:
• Instantly identify system profitability through visual patterns
• Spot outlier trades and risk management issues
• Understand true risk-reward profile of your strategies
• Make data-driven decisions for strategy optimization
• Professional presentation suitable for performance reporting
Disclaimer & Risk Considerations:
Important: Historical performance metrics, including positive Expected Value (EV), do not guarantee future trading success. Statistical measures are derived from finite sample data and subject to inherent limitations:
• Sample Bias: Historical data may not represent future market conditions or regime changes
• Ergodicity Assumption: Markets are non-stationary; past statistical relationships may break down
• Survivorship Bias: Strategies showing positive historical EV may fail during different market cycles
• Parameter Instability: Optimal parameters identified in backtesting often degrade in forward testing
• Transaction Cost Evolution: Slippage, spreads, and commission structures change over time
• Behavioral Factors: Live trading introduces psychological elements absent in backtesting
• Black Swan Events: Extreme market events can invalidate statistical assumptions instantaneously

Mutanabby_AI | Fresh Algo V24Mutanabby_AI | Fresh Algo V24: Advanced Multi-Mode Trading System
Overview
The Mutanabby_AI Fresh Algo V24 represents a sophisticated evolution of multi-component trading systems that adapts to various market conditions through advanced operational configurations and enhanced analytical capabilities. This comprehensive indicator provides traders with multiple signal generation approaches, specialized assistant functions, and dynamic risk management tools designed for professional market analysis across diverse trading environments.
Primary Signal Generation Framework
The Fresh Algo V24 operates through two fundamental signal generation approaches that accommodate different market perspectives and trading philosophies. The Trending Signals Mode serves as the primary trend-following mechanism, combining Wave Trend Oscillator analysis with Supertrend directional signals and Squeeze Momentum breakout detection. This mode incorporates ADX filtering that requires values exceeding 20 to ensure sufficient trend strength exists before signal activation, making it particularly effective during sustained directional market movements where momentum persistence creates profitable trading opportunities.
The Contrarian Signals Mode provides an alternative approach targeting reversal opportunities through extreme market condition identification. This mode activates when the Wave Trend Oscillator reaches critical threshold levels, specifically when readings surpass 65 indicating potential bearish reversal conditions or drop below 35 suggesting bullish reversal opportunities. This methodology proves valuable during overextended market phases where mean reversion becomes statistically probable.
Advanced Filtering Mechanisms
The system incorporates multiple sophisticated filtering mechanisms designed to enhance signal quality and reduce false positive occurrences. The High Volume Filter requires volume expansion confirmation before signal activation, utilizing exponential moving average calculations to ensure institutional participation accompanies price movements. This filter substantially improves signal reliability by eliminating low-conviction breakouts that lack adequate volume support from professional market participants.
The Strong Filter provides additional trend confirmation through 200-period exponential moving average analysis. Long position signals require price action above this benchmark level, while short position signals necessitate price action below it. This ensures strategic alignment with longer-term trend direction and reduces the probability of trading against major market movements that could invalidate shorter-term signals.
Cloud Filter Configuration System
The Fresh Algo V24 offers four distinct cloud filter configurations, each optimized for specific trading timeframes and market approaches. The Smooth Cloud Filter utilizes the mathematical relationship between 150-period and 250-period exponential moving averages, providing stable trend identification suitable for position trading strategies. This configuration generates signals exclusively when price action aligns with cloud direction, creating a more deliberate but highly reliable signal generation process.
The Swing Cloud Filter employs modified Supertrend calculations with parameters specifically optimized for swing trading timeframes. This filter achieves optimal balance between responsiveness and stability, adapting effectively to medium-term price movements while filtering excessive market noise that typically affects shorter-term analytical systems.
For active intraday traders, the Scalping Cloud Filter utilizes accelerated Supertrend calculations designed to capture rapid trend changes effectively. This configuration provides enhanced signal generation frequency suitable for compressed timeframe strategies. The advanced Scalping+ Cloud Filter incorporates Hull Moving Average confirmation, delivering maximum responsiveness for ultra-short-term trading while maintaining signal quality through additional momentum validation processes.
Specialized Assistant Functionality
The system includes two distinct assistant modes that provide supplementary market analysis capabilities. The Trend Assistant Mode activates advanced cloud analysis overlays that display dynamic support and resistance zones calculated through adaptive volatility algorithms. These levels automatically adjust to current market conditions, providing visual guidance for identifying trend continuation patterns and potential reversal areas with mathematical precision.
The Trend Tracker Mode concentrates on long-term trend identification by displaying major exponential moving averages with color-coded fill areas that clarify directional bias. This mode maintains visual simplicity while providing comprehensive trend context evaluation, enabling traders to quickly assess broader market direction and align shorter-term strategies accordingly.
Dynamic Risk Management System
The integrated risk management system automatically adapts across all operational modes, calculating stop loss and take profit targets using Average True Range multiples that adjust to current market volatility. This approach ensures consistent risk parameters regardless of selected operational mode while maintaining relevance to prevailing market conditions.
Stop loss placement occurs at dynamically calculated distances from entry points, while three progressive take profit targets establish at customizable ATR multiples respectively. The system automatically updates these levels upon trend direction changes, ensuring current market volatility influences all risk calculations and maintains appropriate risk-reward ratios throughout trade management.
Comprehensive Market Analysis Dashboard
The sophisticated dashboard provides real-time market analysis including volatility measurements, institutional activity assessment, and multi-timeframe trend evaluation across five-minute through four-hour periods. This comprehensive market context assists traders in selecting appropriate operational modes based on current market characteristics rather than relying exclusively on historical performance data.
The multi-timeframe analysis ensures mode selection considers broader market context beyond the primary trading timeframe, improving overall strategic alignment and reducing conflicts between different temporal market perspectives. The dashboard displays market state classification, volatility percentages, institutional activity levels, current trading session information, and trend pressure indicators with professional formatting and clear visual hierarchy.
Enhanced Trading Assistants
The Fresh Algo V24 includes specialized trading assistant features that complement the primary signal generation system. The Reversal Dot functionality identifies potential reversal points through Wave Trend Oscillator analysis, displaying visual indicators when crossover conditions occur at extreme levels. These reversal indicators provide early warning signals for potential trend changes before they appear in the primary signal system.
The Dynamic Take Profit Labels feature automatically identifies optimal profit-taking opportunities through RSI threshold analysis, marking potential exit points at multiple levels for long positions and corresponding levels for short positions. This automated profit management system helps traders optimize exit timing without requiring constant manual monitoring of technical indicators.
Advanced Alert System
The comprehensive alert system accommodates all operational modes while providing granular notification control for various signal types and risk management events. Traders can configure separate alerts for normal buy signals, strong buy signals, normal sell signals, strong sell signals, stop loss triggers, and individual take profit target achievements.
Cloud crossover alerts notify traders when trend direction changes occur, providing early indication of potential strategy adjustments. The alert system includes detailed trade setup information, timeframe data, and relevant entry and exit levels, ensuring traders receive complete context for informed decision-making without requiring constant chart monitoring.
Technical Foundation Architecture
The Fresh Algo V24 combines multiple proven technical analysis components including Wave Trend Oscillator for momentum assessment, Supertrend for directional bias determination, Squeeze Momentum for volatility analysis, and various exponential moving averages for trend confirmation. Each component contributes specific market insights while the unified system provides comprehensive market evaluation through their mathematical integration.
The multi-component approach reduces dependency on individual indicator limitations while leveraging the analytical strengths of each technical tool. This creates a robust analytical framework capable of adapting to diverse market conditions through appropriate mode selection and parameter optimization, ensuring consistent performance across varying market environments.
Market State Classification
The indicator incorporates advanced market state classification through ADX analysis, distinguishing between trending, ranging, and transitional market conditions. This classification system automatically adjusts signal sensitivity and filtering parameters based on current market characteristics, optimizing performance for prevailing conditions rather than applying static analytical approaches.
The volatility measurement system calculates current market activity levels as percentages, providing quantitative assessment of market energy and helping traders select appropriate operational modes. Institutional activity detection through volume analysis ensures signal generation aligns with professional market participation patterns.
Implementation Strategy Considerations
Successful implementation requires careful matching of operational modes to prevailing market conditions and individual trading objectives. Trending modes demonstrate optimal performance during directional markets with sustained momentum characteristics, while contrarian modes excel during range-bound or overextended market conditions where reversal probability increases.
The cloud filter configurations provide varying degrees of confirmation strength, with smoother settings reducing false signal occurrence at the expense of some responsiveness to price changes. Traders must balance signal quality against signal frequency based on their risk tolerance and available trading time, utilizing the comprehensive customization options to optimize performance for their specific requirements.
Multi-Timeframe Integration
The system provides seamless multi-timeframe analysis through the integrated dashboard, displaying trend alignment across multiple time horizons from five-minute through four-hour periods. This analysis helps traders understand broader market context and avoid conflicts between different temporal perspectives that could compromise trade outcomes.
Session analysis identifies current trading session characteristics, providing context for expected market behavior patterns and helping traders adjust their approach based on typical session volatility and participation levels. This geographic market awareness enhances strategic decision-making and improves timing for trade execution.
Advanced Visualization Features
The indicator includes sophisticated visualization capabilities through gradient candle coloring based on MACD analysis, providing immediate visual feedback on momentum strength and direction. This enhancement allows rapid market assessment without requiring detailed indicator analysis, improving efficiency for traders managing multiple instruments simultaneously.
The cloud visualization system uses color-coded fill areas to clearly indicate trend direction and strength, with automatic adaptation to selected operational modes. This visual clarity reduces analytical complexity while maintaining comprehensive market information display through professional chart presentation.
Performance Optimization Framework
The Fresh Algo V24 incorporates performance optimization features including signal strength classification, automatic parameter adjustment based on market conditions, and dynamic filtering that adapts to current volatility levels. These optimizations ensure consistent performance across varying market environments while maintaining signal quality standards.
The system automatically adjusts sensitivity levels based on selected operational modes, ensuring appropriate responsiveness for different trading approaches. This adaptive framework reduces the need for manual parameter adjustments while maintaining optimal performance characteristics for each operational configuration.
Conclusion
The Mutanabby_AI Fresh Algo V24 represents a comprehensive solution for professional trading analysis, combining multiple analytical approaches with advanced visualization and risk management capabilities. The system's strength lies in its adaptive multi-mode design and sophisticated filtering mechanisms, providing traders with versatile tools for various market conditions and trading styles.
Success with this system requires understanding the relationship between different operational modes and their optimal application scenarios. The comprehensive dashboard and alert system provide essential market context and trade management support, enabling systematic approach to market analysis while maintaining flexibility for individual trading preferences.
The indicator's sophisticated architecture and extensive customization options make it suitable for traders at all experience levels, from those seeking systematic signal generation to advanced practitioners requiring comprehensive market analysis tools. The multi-timeframe integration and adaptive filtering ensure consistent performance across diverse market conditions while providing clear guidelines for strategic implementation.

DTFX Algo Zones [SamuraiJack Mod]CME_MINI:NQ1!
Credits
This indicator is a modified version of an open-source tool originally developed by Lux Algo. I literally modded their indicator to create the DTFX Algo Zones version, incorporating additional features and refinements. Special thanks to Lux Algo for their original work and for providing the open-source code that made this development possible.
Introduction
DTFX Algo Zones is a technical analysis indicator designed to automatically identify key supply and demand zones on your chart using market structure and Fibonacci retracements. It helps traders spot high-probability reversal areas and important support/resistance levels at a glance. By detecting shifts in market structure (such as Break of Structure and Change of Character) and highlighting bullish or bearish zones dynamically, this tool provides an intuitive framework for planning trades. The goal is to save traders time and improve decision-making by focusing attention on the most critical price zones where market bias may confirm or reverse.
Logic & Features
• Market Structure Shift Detection (BOS & CHoCH): The indicator continuously monitors price swings and marks significant structure shifts. A Break of Structure (BOS) occurs when price breaks above a previous swing high or below a swing low, indicating a continuation of the current trend. A Change of Character (ChoCH) is detected when price breaks in the opposite direction of the prior trend, often signaling an early trend reversal. These moments are visually marked on the chart, serving as anchor points for new zones. By identifying BOS and ChoCH in real-time, the DTFX Algo Zones indicator ensures you’re aware of key trend changes as they happen.
• Auto-Drawn Fibonacci Supply/Demand Zones: Upon a valid structure shift, the indicator plots a Fibonacci-based zone between the breakout point and the preceding swing high/low (the source of the move). This creates a shaded area or band of Fibonacci retracement levels (for example 38.2%, 50%, 61.8%, etc.) representing a potential support zone in an uptrend or resistance zone in a downtrend. These supply/demand zones are derived from the natural retracement of the breakout move, highlighting where price is likely to pull back. Each zone is essentially an auto-generated Fibonacci retracement region tied to a market structure event, which traders can use to anticipate where the next pullback or bounce might occur.
• Dynamic Bullish and Bearish Zones: The DTFX Algo Zones indicator distinguishes bullish vs. bearish zones and updates them dynamically as new price action unfolds. Bullish zones (formed after bullish BOS/ChoCH) are typically highlighted in one color (e.g. green or blue) to indicate areas of demand/support where price may bounce upward. Bearish zones (formed after bearish BOS/ChoCH) are shown in another color (e.g. red/orange) to mark supply/resistance where price may stall or reverse downward. This color-coding and real-time updating allow traders to instantly recognize the market bias: for instance, a series of bullish zones implies an uptrend with multiple support levels on pullbacks, while consecutive bearish zones indicate a downtrend with resistance overhead. As old zones get invalidated or new ones appear, the chart remains current with the latest key levels, eliminating clutter from outdated levels.
• Flexible Customization: The indicator comes with several options to tailor the zones to your trading style. You can filter which zones to display – for example, show only the most recent N zones or limit to only bullish or only bearish zones – helping declutter the chart and focus on recent, relevant levels. There are settings to control zone extension (how far into the future the zones are drawn) and to automatically invalidate zones once they’re no longer relevant (for instance, if price fully breaks through a zone or a new structure shift occurs that supersedes it). Additionally, the Fibonacci retracement levels within each zone are customizable: you can choose which retracement percentages to plot, adjust their colors or line styles, and decide whether to fill the zone area for visibility. This flexibility ensures the DTFX Algo Zones can be tuned for different markets and strategies, whether you want a clean minimalist look or detailed zones with multiple internal levels.
Best Use Cases
DTFX Algo Zones is a versatile indicator that can enhance various trading strategies. Some of its best use cases include:
• Identifying High-Probability Reversal Zones: Each zone marks an area where price has a higher likelihood of stalling or reversing because it reflects a significant prior swing and Fibonacci retracement. Traders can watch these zones for entry opportunities when the market approaches them, as they often coincide with order block or strong supply/demand areas. This is especially useful for catching trend reversals or pullbacks at points where risk is lower and potential reward is higher.
• Spotting Key Support and Resistance: The automatically drawn zones act as dynamic support (below price) and resistance (above price) levels. Instead of manually drawing Fibonacci retracements or support/resistance lines, you get an instant map of the key levels derived from recent price action. This helps in quickly identifying where the next bounce (support) or rejection (resistance) might occur. Swing traders and intraday traders alike can use these zones to set alerts or anticipate reaction areas as the market moves.
• Trend-Following Entries: In a trending market, the indicator’s zones provide ideal areas to join the trend on pullbacks. For example, in an uptrend, when a new bullish zone is drawn after a BOS, it indicates a fresh demand zone – buying near the lower end of that zone on a pullback can offer a low-risk entry to ride the next leg up. Similarly, in a downtrend, selling rallies into the highlighted supply zones can position you in the direction of the prevailing trend. The zones effectively serve as a roadmap of the trend’s structure, allowing trend traders to buy dips and sell rallies with greater confidence.
• Mean-Reversion and Range Trading: Even in choppy or range-bound markets, DTFX Algo Zones can help find mean-reversion trades. If price is oscillating sideways, the zones at extremes of the range might mark where momentum is shifting (ChoCH) and price could swing back toward the mean. A trader might fade an extended move when it reaches a strong zone, anticipating a reversion. Additionally, if multiple zones cluster in an area across time (creating a zone overlap), it often signifies a particularly robust support/resistance level ideal for range trading strategies.
In all these use cases, the indicator’s ability to filter out noise and highlight structurally important levels means traders can focus on higher-probability setups and make more informed trading decisions.
Strategy – Pullback Trading with DTFX Algo Zones
One of the most effective ways to use the DTFX Algo Zones indicator is trading pullbacks in the direction of the trend. Below is a step-by-step strategy to capitalize on pullbacks using the zones, combining the indicator’s signals with sound price action analysis and risk management:
1. Identify a Market Structure Shift and Trend Bias: First, observe the chart for a recent BOS or ChoCH signal from the indicator. This will tell you the current trend bias. For instance, a bullish BOS/ChoCH means the market momentum has shifted upward (bullish bias), and a new demand zone will be drawn. A bearish structure break indicates downward momentum and creates a supply zone. Make sure the broader context supports the bias (e.g., if multiple higher timeframe zones are bullish, focus on long trades).
2. Wait for the Pullback into the Zone: Once a new zone appears, don’t chase the price immediately. Instead, wait for price to retrace back into that highlighted zone. Patience is key – let the market come to you. For a bullish setup, allow price to dip into the Fibonacci retracement zone (demand area); for a bearish setup, watch for a rally into the supply zone. Often, the middle of the zone (around the 50% retracement level) can be an optimal area where price might slow down and pivot, but it’s wise to observe price behavior across the entire zone.
3. Confirm the Entry with Price Action & Confluence: As price tests the zone, look for confirmation signals before entering the trade. This can include bullish reversal candlestick patterns (for longs) or bearish patterns (for shorts) such as engulfing candles, hammers/shooting stars, or doji indicating indecision turning to reversal. Additionally, incorporate confluence factors to strengthen the setup: for example, check if the zone overlaps with a key moving average, a round number price level, or an old support/resistance line from a higher timeframe. You might also use an oscillator (like RSI or Stochastic) to see if the pullback has reached oversold conditions in a bullish zone (or overbought in a bearish zone), suggesting a bounce is likely. The more factors aligning at the zone, the more confidence you can have in the trade. Only proceed with an entry once you see clear evidence of buyers defending a demand zone or sellers defending a supply zone.
4. Enter the Trade and Manage Risk: When you’re satisfied with the confirmation (e.g., price starts to react positively off a demand zone or shows rejection wicks in a supply zone), execute your entry in the direction of the original trend. Immediately set a stop-loss order to control risk: for a long trade, a common placement is just below the demand zone (a few ticks/pips under the swing low that formed the zone); for a short trade, place the stop just above the supply zone’s high. This way, if the zone fails and price continues beyond it, your loss is limited. Position size the trade so that this stop-loss distance corresponds to a risk you are comfortable with (for example, 1-2% of your trading capital).
5. Take Profit Strategically: Plan your take-profit targets in advance. A conservative approach is to target the origin of the move – for instance, in a long trade, you might take profit as price moves back up to the swing high (the 0% Fibonacci level of the zone) or the next significant zone or resistance level above. This often yields at least a 1:1 reward-to-risk ratio if you entered around mid-zone. More aggressive trend-following traders may leave a portion of the position running beyond the initial target, aiming for a larger move in line with the trend (for example, new higher highs in an uptrend). You can also trail your stop-loss upward behind new higher lows (for longs) or lower highs (for shorts) as the trend progresses, locking in profit while allowing for further gains.
6. Monitor Zone Invalidation: Even after entering, keep an eye on the behavior around the zone and any new zones that may form. If price fails to bounce and instead breaks decisively through the entire zone, respect that as an invalidation – the market may be signaling a deeper reversal or that the signal was false. In such a case, it’s better to exit early or stick to your stop-loss than to hold onto a losing position. The indicator will often mark or no longer highlight zones that have been invalidated by price, guiding you to shift focus to the next opportunity.
Risk Management Tips:
• Always use a stop-loss and don’t move it farther out in hope. Placing the stop just beyond the zone’s far end (the swing point) helps protect you if the pullback turns into a larger reversal.
• Aim for a favorable risk-to-reward ratio. With pullback entries near the middle or far end of a zone, you can often achieve a reward that equals or exceeds your risk. For example, risking 20 pips to make 20+ pips (1:1 or better) is a prudent starting point. Adjust targets based on market structure – if the next resistance is 50 pips away, consider that upside against your risk.
• Use confluence and context: Don’t take every zone signal in isolation. The highest probability trades come when the DTFX Algo Zone aligns with other analysis (trend direction, chart patterns, higher timeframe support/resistance, etc.). This filtered approach will reduce trades taken in weak zones or counter-trend traps.
• Embrace patience and selectivity: Not all zones are equal. It can be wise to skip very narrow or insignificant zones and wait for those that form after a strong BOS/ChoCH (indicating a powerful move). Larger zones or zones formed during high-volume times tend to produce more reliable pullback opportunities.
• Review and adapt: After each trade, note how price behaved around the zone. If you notice certain Fib levels (like 50% or 61.8%) within the zone consistently provide the best entries, you can refine your approach to focus on those. Similarly, adjust the indicator’s settings if needed – for example, if too many minor zones are cluttering your screen, limit to the last few or increase the structure length parameter to capture only more significant swings.
⸻
By combining the DTFX Algo Zones indicator with disciplined confirmation and risk management, traders can improve their timing on pullback entries and avoid chasing moves. This indicator shines in helping you trade what you see, not what you feel – the clearly marked zones and structure shifts keep you grounded in price action reality. Whether you’re a trend trader looking to buy the dip/sell the rally, or a reversal trader hunting for exhaustion points, DTFX Algo Zones provides a robust visual aid to elevate your trading decisions. Use it as a complementary tool in your analysis to stay on the right side of the market’s structure and enhance your trading performance.

Grid Spot Trading Algorithm V2 - The Quant ScienceGrid Spot Trading Algorithm V2 is the last grid trading algorithm made by our developer team.
Grid Spot Trading Algorithm V2 is a fixed 10-level grid trading algorithm. The grid is divided into an accumulation area (red) and a selling area (green).
In the accumulation area, the algorithm will place new buy orders, selling the long positions on the top of the grid.
BUYING AND SELLING LOGIC
The algorithm places up to 5 limit orders on the accumulation section of the grid, each time the price cross through the middle grid. Each single order uses 20% of the equity.
Positions are closed at the top of the grid by default, with the algorithm closing all orders at the first sell level. The exit level can be adjusted using the user interface, from the first level up to the fifth level above.
CONFIGURING THE ALGORITHM
1) Add it to the chart: Add the script to the current chart that you want to analyze.
2) Select the top of the grid: Confirm a price level with the mouse on which to fix the top of the grid.
3) Select the bottom of the grid: Confirm a price level with the mouse on which to fix the bottom of the grid.
4) Wait for the automatic creation of the grid.
USING THE ALGORITHM
Once the grid configuration process is completed, the algorithm will generate automatic backtesting.
You can add a stop loss that destroys the grid by setting the destruction price and activating the feature from the user interface. When the stop loss is activated, you can view it on the chart.
FunctionArrayMaxSubKadanesAlgorithmLibrary "FunctionArrayMaxSubKadanesAlgorithm"
Implements Kadane's maximum sum sub array algorithm.
size(samples) Kadanes algorithm.
Parameters:
samples : float array, sample data values.
Returns: float.
indices(samples) Kadane's algorithm with indices.
Parameters:
samples : float array, sample data values.
Returns: tuple with format .

Ichimoku Cloud Strategy Long Only [Bitduke]Slightly modificated and optimized for Pine Script 4.0, Ichimoku Cloud Strategy which, suddenly, good suitable for the several crypto assets.
Details:
Enter position when conversion line crosses base line up, and close it when the opposite happens.
Additional condition for open / close the trade is lagging span, it should be higher than cloud to open position and below - to close it.
Backtesting:
Backtested on SOLUSDT ( FTX, Binance )
+150% for 2021 year, 8% dd
+191% for all time, 32% dd
Disadvantages:
- Small number of trades
- Need to vary parameters for different coins (not very robust)
Should be tested carefully for other coins / stock market. Different parameters could be needed or even algo modifications.
Strategy doesn't repaint.
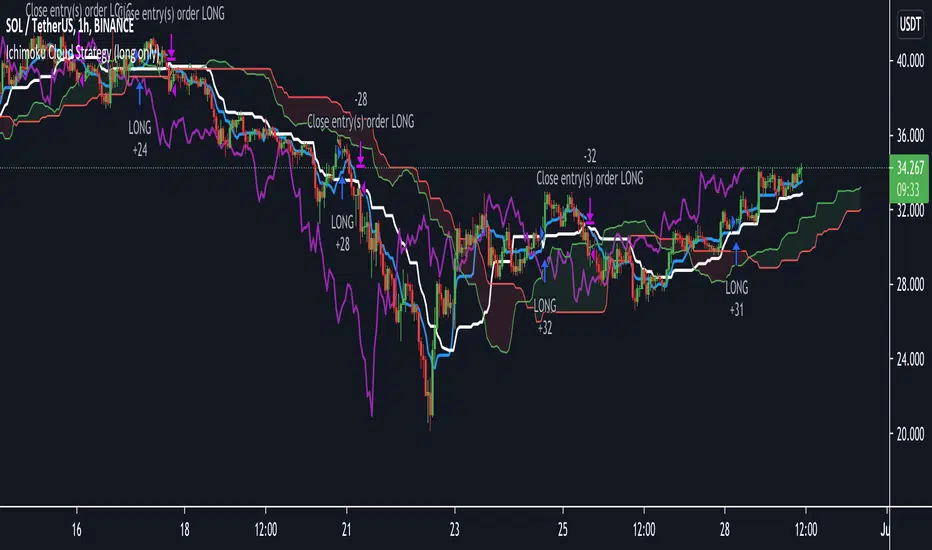
ICT Algo: Sweep + MSS + High Prob FVG/IFVGThis script is a comprehensive execution tool based on Inner Circle Trader (ICT) concepts, specifically designed to identify high-probability entries by combining Liquidity Sweeps, Market Structure Shifts (MSS), and Fair Value Gaps (FVG/IFVG).
Unlike standard FVG indicators that highlight every gap on the chart, this "Algo" version filters for gaps that occur specifically after a liquidity purge and a shift in structure, ensuring you are only looking at setups with institutional backing.
How It Works
The script follows a strict 3-step validation process before plotting a signal:
Liquidity Sweep (The Context): The script tracks Higher Timeframe (HTF) levels including Previous Day High/Low, Weekly High/Low, and Monthly High/Low. A setup is only considered valid if price has recently "swept" one of these levels, indicating a hunt for liquidity.
Market Structure Shift (The Confirmation): Once a sweep occurs, the script looks for a displacement in the opposite direction. It identifies a "Pivot High/Low" (customizable length) and waits for a candle body to close beyond it (MSS).
Filtered Entry (The Trigger): * FVG: Plots a standard Fair Value Gap if it forms within a "Deep Value" zone (Discount for longs, Premium for shorts).
IFVG (Inversion FVG): Highlights failed FVGs that have been reclaimed by price to act as support or resistance.
Key Features
Multi-Timeframe Liquidity Filters: Automatically plots PDH/L, PWH/L, PMH/L, and PYH/L. You can toggle which levels act as your sweep triggers.
Deep Value Logic: The script uses built-in logic to ensure Bullish FVGs are only highlighted when price is below a key liquidity level (Discount), and Bearish FVGs when price is above (Premium).
Dynamic Box Management: To keep your chart clean, boxes for FVGs and IFVGs are automatically shortened ("cut") once they are mitigated by price.
Inversion Logic: Includes a specialized toggle for Inversion Fair Value Gaps, allowing you to trade "failed" gaps that flip their polarity.
Settings & Customization
Entry Setup Bias: Choose to see only Bullish, only Bearish, or Both setups.
MSS Pivot Length: Adjust how "sensitive" the Market Structure Shift detection is. A higher number requires a more significant swing to be broken.
Sweep Lookback: Defines how many bars back the script looks for a liquidity sweep to remain "active" for a setup.
Include Opens: Optional toggle to include Previous Day/Week/Month Opens as liquidity points.
Usage Tips
The Golden Setup: Look for a sweep of a Previous Day High, followed by a Bearish MSS, and an entry at the Red FVG box.
Risk Management: This indicator is designed for entry identification. Always use stop losses (usually placed above/below the candle that created the FVG or the MSS swing point).
Timeframes: Best used on execution timeframes (1m, 5m, 15m) while the script handles the HTF levels automatically.
Disclaimer: This script is an educational tool and does not constitute financial advice. Trading involves significant risk. Past performance of a strategy does not guarantee future results.
Credits: Concepts based on the teachings of Michael J. Huddleston (ICT).

ICT Macro Tracker - Study Version (Original by toodegrees)This indicator is a modified study version of the ICT Algorithmic Macro Tracker by toodegrees, based on the original open-source script available at The original indicator plots ICT Macro windows on the chart, corresponding to specific time [ periods when the Interbank Price Delivery Algorithm undergoes checks/instructions (aka "macros") for the price engine to reprice to an area of liquidity or inefficiency.
This study version adds functionality to hide bars outside macro periods. When enabled, the indicator draws boxes that cover the full chart height during non-macro periods, obscuring those bars so only macro periods are visible. This helps focus on macro-only price action. The feature is configurable, allowing users to enable or disable it and customize the box color. All original functionality remains intact.

PriceLevels GBGoldbach Price Levels – Identify Algorithmic Key Zones
This open-source indicator is designed to help traders identify potential algorithmic key zones by highlighting price levels ending with specific numbers such as 03, 11, 29, 35, 65, and 71. These levels may act as inflection points or hesitation areas based on observed behavioral patterns in price movement.
What It Does:
📌 Scans and plots horizontal price levels where the price ends with one of the selected number combinations
🎯 Toggle on/off visibility for each number ending
🎨 Customize color and thickness for each level
🏷️ Shows price labels at the end of each line
🌗 Label styles (color/transparency) are adjustable for both dark and light chart themes
🧠 Why Use It:
This tool is ideal for discretionary traders who study market structure through static price anchors. It provides a visual reference for recurring numerical levels that may be used in algorithmic trading models or serve as psychological price zones.
⚠️ Disclaimer:
This script is open-source and intended for educational and analytical purposes only. No trading signals or performance guarantees are provided. Please use your own judgment when applying this tool in a trading context.
Market Structure AlgoThe "Market Structure Algo" (MS Algo) is a comprehensive tool developed by OmegaTools. This advanced indicator is designed to analyze the market's structure through a combination of pivot highs and lows, creating a nuanced understanding of potential market movements.
Core Functionality:
- Internal and External Market Structure (MS): The MS Algo differentiates between internal and external market structures by analyzing pivot points over different periods. This dual analysis allows for a deeper understanding of short-term and long-term market trends.
- Zone Distance and Visualization: The indicator introduces a novel approach to visualizing potential areas of interest or 'zones' around pivot points, adjustable through the 'Zone Distance' setting. This feature enhances the visual representation of zone created on the chart that can be used as a support and resistance area.
- Dynamic Signal Generation: Utilizing a comprehensive algorithm, the MS Algo identifies potential signals for entering and exiting trades based on the internal market structure. These signals are visually represented on the chart, aiding in decision-making. These signals are based on the acceptance and confirmed breakout or the refusal of the pivot points by the price.
Operational Mechanism:
- The MS Algo calculates pivot highs and lows over specified periods (input by the user) to determine the market's current structure. It then evaluates the market's position relative to these pivot points to assign a market structure score, which can range from bullish to bearish extremes.
- Signals for long and short positions, as well as exits, are generated based on the interaction between the close price and these pivot points.
- Additionally, the indicator plots zones around the moving average, adjusted for the ATR and the specified 'Zone Distance,' providing a visual guide to areas where the market might find support or resistance.
Usage Guidelines:
- To apply the MS Algo to your TradingView charts, adjust the 'Internal MS' and 'External MS' settings to align with your analysis preferences. The 'Zone Distance' input allows for customization of the zone visualization feature.
- The color-coded signals and zone fillings serve as guides to understanding the current market structure and potential areas of interest. These should be interpreted within the context of a broader trading strategy and risk management framework.
Understanding the Indicator's Originality:
The MS Algo stands out due to its unique blend of pivot analysis and zone visualization, providing traders with a detailed view of the market's structure that goes beyond traditional indicators. Its originality lies in the methodological integration of these components to offer a tool that enhances market analysis.
Responsible Use Disclaimer:
The financial markets are unpredictable, and the MS Algo is designed to serve as an analytical tool within a trader's arsenal, not a standalone solution for trading decisions. Traders should use this tool judiciously, alongside comprehensive market analysis and sound risk management practices. It's important to understand that the MS Algo does not guarantee trading success nor does it claim to predict specific price movements. Trading involves risks, including the potential loss of capital.
