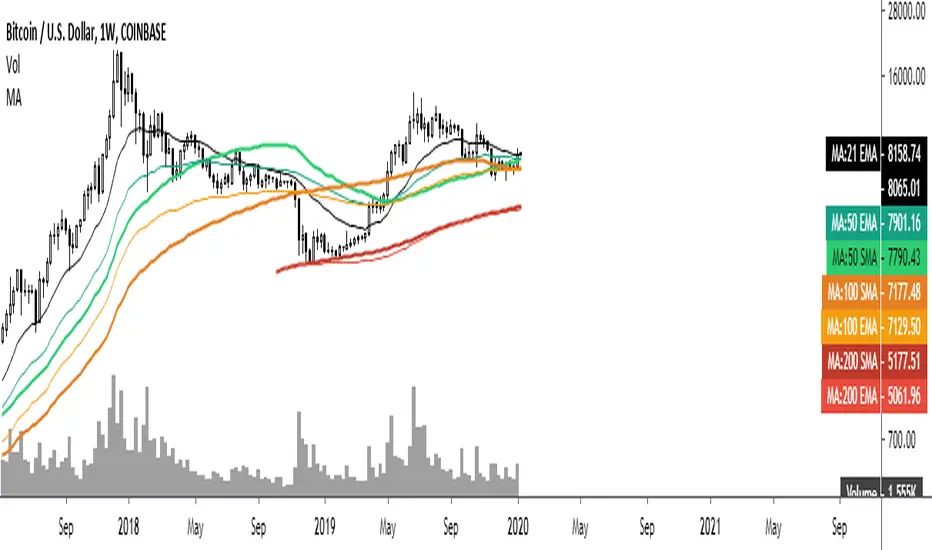
Common Moving averages ( 4 EMA + 3 SMA)Common moving averages used are included in the script. Customize them as per your wishes.
MA's set as default are
21 EMA
50 EMA , SMA
100 EMA , SMA
200 EMA , SMA
Please favorite it if you like it! Thanks!
ابحث في النصوص البرمجية عن "one一季度财报"
RSI + Composite Index [SHK]One of the most powerful indicator based and divergence strategies i have ever seen was made by Constance Brown.
The Composite Index:
The best way to think of the Composite Index as it applies to the RSI is to think of the RSI as Windows 3.0 and the Composite Index as Windows 10. Constance Brown discovered that the RSI, while it does create and detect divergences, does is not as accurate as it could be. It’s a bit of an oxymoron to say this but the RSI is a momentum indicator without any momentum calculation attached to it. The RSI actually misses a significant amount of important moves and even generates some bad moves. What Constance Brown did with the RSI is to input a momentum calculation within the RSI itself.
Usage:
1. Check hidden and regular divergences on RSI+COMPOSITE_INDEX and PRICE+COMPOSITE_INDEX.
2. After finding divergence wait for COMPOSITE_INDEX to cross under/over it's moving averages to trigger.
Useful Note:
"RSI overbought/oversold as filter", "RSI and COMPOSITE_INDEX trendline as trigger", "RSI 50 Over/Under as trend direction detection", ... can be add to this strategy.
Enjoy!

Leeloo Quadruple (4x) Simple Moving AverageOne-stop shop for all of the simple moving averages because editing separately is annoying.

ATR stop and threshold valueOne can use the average true range for both entries and stops. A possible way to reduce false breakouts is to enter (say) at 0.5 * atr above the breakout level. Then you could use a 1.0*atr for a stop setting. This indicator allows you to set entries and stops for both long and short setups directly on the chart. I use it with breakout systems as it allows me to easily setup my trades.

Multiple Simple Moving AveragesOne no-fuss indicator for SMA for 6 different time period (10, 20, 50, 100, 200, 250), styled with sharp and thin line for shorter time period to light-coloured and wide line for longer time period.

Multi Color Normalized MACD + Candles (NMACD) [cI8DH]One simple indicator for volatility, divergence and relative momentum
Features:
- Normalized MACD (by slow MA)
- Candle MACD (fast MA length is set to 0 in candle mode, i.e. price minus slow MA)
- Multi color histogram
- Background coloring based on MACD direction
- Choice of different MA types (Exponential, Simple, Weighted, Smoothed, Triple EMA)
- Triple EMA smoothing
Benefits of normalization:
- Absolutely better than RSI for comparing across different periods and assets
Applications and benefits of candle visualization:
- Zero cross: most traders use MAs overlaid on the main chart and look for price distance and MA cross visually. In candle mode, this indicator measures the difference between price and the slow moving MA. When this indicator crosses zero, it means price is crossing the slow moving MA.
- Divergence: full candle visualization (OHLC) is not possible for most other indicators. Candle visualization allows measuring divergence between price high, low and close simultaneously. Some trades incorrectly measure divergence between high, low of price against indicator tops and bottoms while having the indicator input set to default (usually close). With this indicator, you don't need to worry about such complexities.
Recommended setting:
- Enjoy candle mode :)
- Source set to hlc3
Fibonacci Exponential Moving Averages (+ 200EMA)One indicator to rule them all...
So here you have the fib based EMA`s (8,3,21,55) plus I added the 200 EMA cause I love it and should give you the complete picture. Have fun!
To add click on "Add to favorite scripts" and then select in your TV settings.
*Thanks to behind_crypto for publishing the base version of the script!*
EMA50Diff & MACD StrategyOne of my attempts to create a strategy for BTC.
Its a combination of EMA50Diff (the difference between spot and EMA50) and MACD.
Buy signal if (EMA50Diff) < -(EMADiffThreshold),
(MACD bearish crossunder),
(MACD) < -(MACDThreshold),
(EMA50Diff) > (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) < (EMA50Diff 2 candles ago)
Sell signal if (EMA50Diff) > (EMADiffThreshold),
(MACD bullish crossover),
(MACD) > (MACDThreshold),
(EMA50Diff) < (EMA50Diff 1 candle ago),
(EMA50Diff 1 candle ago) > (EMA50Diff 2 candles ago)
Exit either when target or stoploss get reached.
Initial capital is set to 100k and its currently going all-in on every trade but im looking for a better way to handle position sizes already..
Also i included slippage of 30 ticks and exchange commission of 0.15% (e.g. 2x BitMEX market taker fee)
Works best on 15m on bitfinex, bitstamp and gdax and i'm still trying to optimize it for bitmex too, will update when i got there..

RSI / Stoch / Stoch RSI (SRSI) Overlay [SigmaDraconis]One indicator combining RSI, Stochastic Oscillator and Stochastic RSI in one.
Credits for rwhiteside and his RSI / Stoch RSI Overlay indicator who served as inspiration to all three.
I believe this will be very useful to a lot of people.
If you like, use and i prove to be , you can contribute to my
TIP JAR :

DAX/CAC40 SpreadOne more spread. You can change symbol by click on the input symbol window, and use anyone you like
USDCAD/WTI SpreadOne more spread , this is USDCAD/WTI . Is the change of the moment of this 2 security.
One White Soldier StudyThis shows a green indicator on this study (17Jun & 15Aug on TRN) when a bullish candle opens and closes above the prior day's bearish candle, ignoring gap ups. This will only show in the DAILY chart, not intraday.

Ehlers Simple Cycle Indicator [LazyBear]One of the early cycle indicators from John Ehlers.
Ehlers suggests using this with ITrend (see linked PDF below). Osc/signal crosses identify entry/exit points.
Options page has the usual set of configurable params.
More info:
- Simple Cycle Indicator: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com

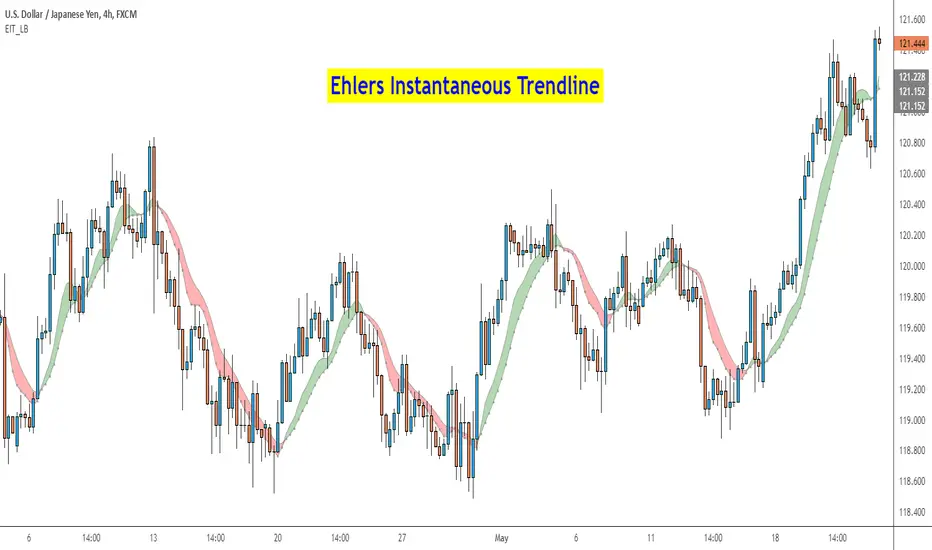
Ehlers Instantaneous Trend [LazyBear]One more to add to the Ehlers collection.
Ehlers Instantaneous Trendline, by John Ehlers, identifies the market trend by doing removing cycle component. I think, this simplicity is what makes it attractive :) To understand Ehlers's thought process behind this, refer to the PDF linked below.
There are atleast 6 variations of this ITrend. This version is from his early presentations.
Is this better than a simple HMA? May be, May be not. I will leave it to you to decide :)
I have added options to show this as a ribbon, and to color bars based on ITrend. Check out the options page.
More info:
- ITrend: www.mesasoftware.com
List of my public indicators: bit.ly
List of my app-store indicators: blog.tradingview.com
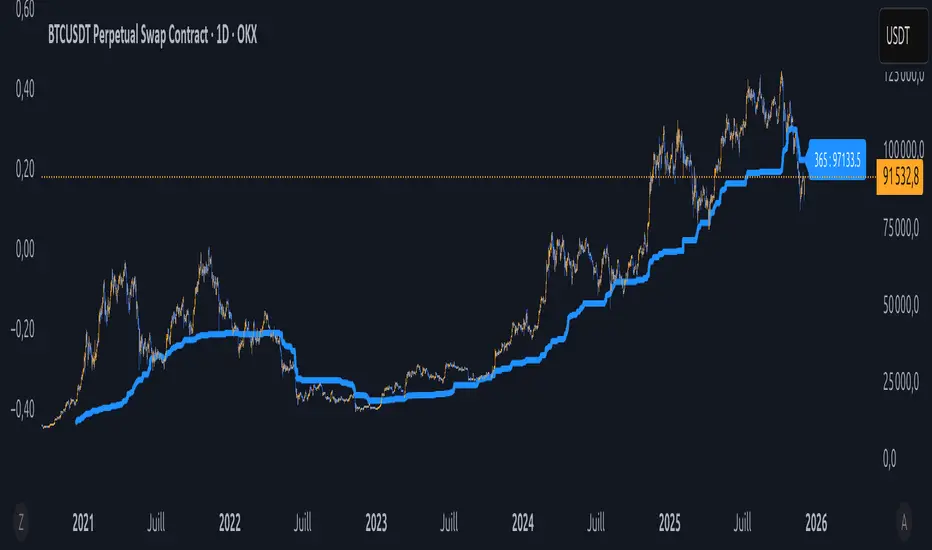
Équilibre du Sentiment – Multi-Périodes (v6)
English
A unique and advanced sentiment indicator based on the harmonic mean of highs and lows over nested rolling windows.
How it works:
The neutral sentiment point is reached when positive sentiment equals negative sentiment, which corresponds to the situation where the percentage between the price and the minimum is equal to the percentage between the maximum and the price.
For each chosen period N, the script calculates N different "neutral feeling" values:
- One using the last 1 bar
- One using the last 2 bars
- …
- One using the last N bars
It then extracts the exact median of these N values using a sorted insertion method (no approximation).
This produces an extremely smooth, non-repainting equilibrium line that represents the true "central sentiment" of the market over the selected lookback.
Features:
- Up to 3 independent periods (365, 52, 26 by default – fully customizable)
- Optional background coloring (green/red) when price is above/below the main curve
- Clean labels on the last bar showing the current value for each active period
- Zero repainting – fully compatible with strategies and alerts
- Highly responsive even with very long periods (up to 3500 bars)
Great for:
- Identifying long-term fair value / equilibrium zones
- Building mean-reversion or breakout systems
Pure Pine Script® v6 – no external libraries, no security calls, no repainting-free.
ValueAtTime█ OVERVIEW
This library is a Pine Script® programming tool for accessing historical values in a time series using UNIX timestamps . Its data structure and functions index values by time, allowing scripts to retrieve past values based on absolute timestamps or relative time offsets instead of relying on bar index offsets.
█ CONCEPTS
UNIX timestamps
In Pine Script®, a UNIX timestamp is an integer representing the number of milliseconds elapsed since January 1, 1970, at 00:00:00 UTC (the UNIX Epoch ). The timestamp is a unique, absolute representation of a specific point in time. Unlike a calendar date and time, a UNIX timestamp's meaning does not change relative to any time zone .
This library's functions process series values and corresponding UNIX timestamps in pairs , offering a simplified way to identify values that occur at or near distinct points in time instead of on specific bars.
Storing and retrieving time-value pairs
This library's `Data` type defines the structure for collecting time and value information in pairs. Objects of the `Data` type contain the following two fields:
• `times` – An array of "int" UNIX timestamps for each recorded value.
• `values` – An array of "float" values for each saved timestamp.
Each index in both arrays refers to a specific time-value pair. For instance, the `times` and `values` elements at index 0 represent the first saved timestamp and corresponding value. The library functions that maintain `Data` objects queue up to one time-value pair per bar into the object's arrays, where the saved timestamp represents the bar's opening time .
Because the `times` array contains a distinct UNIX timestamp for each item in the `values` array, it serves as a custom mapping for retrieving saved values. All the library functions that return information from a `Data` object use this simple two-step process to identify a value based on time:
1. Perform a binary search on the `times` array to find the earliest saved timestamp closest to the specified time or offset and get the element's index.
2. Access the element from the `values` array at the retrieved index, returning the stored value corresponding to the found timestamp.
Value search methods
There are several techniques programmers can use to identify historical values from corresponding timestamps. This library's functions include three different search methods to locate and retrieve values based on absolute times or relative time offsets:
Timestamp search
Find the value with the earliest saved timestamp closest to a specified timestamp.
Millisecond offset search
Find the value with the earliest saved timestamp closest to a specified number of milliseconds behind the current bar's opening time. This search method provides a time-based alternative to retrieving historical values at specific bar offsets.
Period offset search
Locate the value with the earliest saved timestamp closest to a defined period offset behind the current bar's opening time. The function calculates the span of the offset based on a period string . The "string" must contain one of the following unit tokens:
• "D" for days
• "W" for weeks
• "M" for months
• "Y" for years
• "YTD" for year-to-date, meaning the time elapsed since the beginning of the bar's opening year in the exchange time zone.
The period string can include a multiplier prefix for all supported units except "YTD" (e.g., "2W" for two weeks).
Note that the precise span covered by the "M", "Y", and "YTD" units varies across time. The "1M" period can cover 28, 29, 30, or 31 days, depending on the bar's opening month and year in the exchange time zone. The "1Y" period covers 365 or 366 days, depending on leap years. The "YTD" period's span changes with each new bar, because it always measures the time from the start of the current bar's opening year.
█ CALCULATIONS AND USE
This library's functions offer a flexible, structured approach to retrieving historical values at or near specific timestamps, millisecond offsets, or period offsets for different analytical needs.
See below for explanations of the exported functions and how to use them.
Retrieving single values
The library includes three functions that retrieve a single stored value using timestamp, millisecond offset, or period offset search methods:
• `valueAtTime()` – Locates the saved value with the earliest timestamp closest to a specified timestamp.
• `valueAtTimeOffset()` – Finds the saved value with the earliest timestamp closest to the specified number of milliseconds behind the current bar's opening time.
• `valueAtPeriodOffset()` – Finds the saved value with the earliest timestamp closest to the period-based offset behind the current bar's opening time.
Each function has two overloads for advanced and simple use cases. The first overload searches for a value in a user-specified `Data` object created by the `collectData()` function (see below). It returns a tuple containing the found value and the corresponding timestamp.
The second overload maintains a `Data` object internally to store and retrieve values for a specified `source` series. This overload returns a tuple containing the historical `source` value, the corresponding timestamp, and the current bar's `source` value, making it helpful for comparing past and present values from requested contexts.
Retrieving multiple values
The library includes the following functions to retrieve values from multiple historical points in time, facilitating calculations and comparisons with values retrieved across several intervals:
• `getDataAtTimes()` – Locates a past `source` value for each item in a `timestamps` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified timestamps.
• `getDataAtTimeOffsets()` – Finds a past `source` value for each item in a `timeOffsets` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified millisecond offsets behind the current bar's opening time.
• `getDataAtPeriodOffsets()` – Finds a past value for each item in a `periods` array. Each retrieved value's timestamp represents the earliest time closest to one of the specified period offsets behind the current bar's opening time.
Each function returns a tuple with arrays containing the found `source` values and their corresponding timestamps. In addition, the tuple includes the current `source` value and the symbol's description, which also makes these functions helpful for multi-interval comparisons using data from requested contexts.
Processing period inputs
When writing scripts that retrieve historical values based on several user-specified period offsets, the most concise approach is to create a single text input that allows users to list each period, then process the "string" list into an array for use in the `getDataAtPeriodOffsets()` function.
This library includes a `getArrayFromString()` function to provide a simple way to process strings containing comma-separated lists of periods. The function splits the specified `str` by its commas and returns an array containing every non-empty item in the list with surrounding whitespaces removed. View the example code to see how we use this function to process the value of a text area input .
Calculating period offset times
Because the exact amount of time covered by a specified period offset can vary, it is often helpful to verify the resulting times when using the `valueAtPeriodOffset()` or `getDataAtPeriodOffsets()` functions to ensure the calculations work as intended for your use case.
The library's `periodToTimestamp()` function calculates an offset timestamp from a given period and reference time. With this function, programmers can verify the time offsets in a period-based data search and use the calculated offset times in additional operations.
For periods with "D" or "W" units, the function calculates the time offset based on the absolute number of milliseconds the period covers (e.g., `86400000` for "1D"). For periods with "M", "Y", or "YTD" units, the function calculates an offset time based on the reference time's calendar date in the exchange time zone.
Collecting data
All the `getDataAt*()` functions, and the second overloads of the `valueAt*()` functions, collect and maintain data internally, meaning scripts do not require a separate `Data` object when using them. However, the first overloads of the `valueAt*()` functions do not collect data, because they retrieve values from a user-specified `Data` object.
For cases where a script requires a separate `Data` object for use with these overloads or other custom routines, this library exports the `collectData()` function. This function queues each bar's `source` value and opening timestamp into a `Data` object and returns the object's ID.
This function is particularly useful when searching for values from a specific series more than once. For instance, instead of using multiple calls to the second overloads of `valueAt*()` functions with the same `source` argument, programmers can call `collectData()` to store each bar's `source` and opening timestamp, then use the returned `Data` object's ID in calls to the first `valueAt*()` overloads to reduce memory usage.
The `collectData()` function and all the functions that collect data internally include two optional parameters for limiting the saved time-value pairs to a sliding window: `timeOffsetLimit` and `timeframeLimit`. When either has a non-na argument, the function restricts the collected data to the maximum number of recent bars covered by the specified millisecond- and timeframe-based intervals.
NOTE : All calls to the functions that collect data for a `source` series can execute up to once per bar or realtime tick, because each stored value requires a unique corresponding timestamp. Therefore, scripts cannot call these functions iteratively within a loop . If a call to these functions executes more than once inside a loop's scope, it causes a runtime error.
█ EXAMPLE CODE
The example code at the end of the script demonstrates one possible use case for this library's functions. The code retrieves historical price data at user-specified period offsets, calculates price returns for each period from the retrieved data, and then populates a table with the results.
The example code's process is as follows:
1. Input a list of periods – The user specifies a comma-separated list of period strings in the script's "Period list" input (e.g., "1W, 1M, 3M, 1Y, YTD"). Each item in the input list represents a period offset from the latest bar's opening time.
2. Process the period list – The example calls `getArrayFromString()` on the first bar to split the input list by its commas and construct an array of period strings.
3. Request historical data – The code uses a call to `getDataAtPeriodOffsets()` as the `expression` argument in a request.security() call to retrieve the closing prices of "1D" bars for each period included in the processed `periods` array.
4. Display information in a table – On the latest bar, the code uses the retrieved data to calculate price returns over each specified period, then populates a two-row table with the results. The cells for each return percentage are color-coded based on the magnitude and direction of the price change. The cells also include tooltips showing the compared daily bar's opening date in the exchange time zone.
█ NOTES
• This library's architecture relies on a user-defined type (UDT) for its data storage format. UDTs are blueprints from which scripts create objects , i.e., composite structures with fields containing independent values or references of any supported type.
• The library functions search through a `Data` object's `times` array using the array.binary_search_leftmost() function, which is more efficient than looping through collected data to identify matching timestamps. Note that this built-in works only for arrays with elements sorted in ascending order .
• Each function that collects data from a `source` series updates the values and times stored in a local `Data` object's arrays. If a single call to these functions were to execute in a loop , it would store multiple values with an identical timestamp, which can cause erroneous search behavior. To prevent looped calls to these functions, the library uses the `checkCall()` helper function in their scopes. This function maintains a counter that increases by one each time it executes on a confirmed bar. If the count exceeds the total number of bars, indicating the call executes more than once in a loop, it raises a runtime error .
• Typically, when requesting higher-timeframe data with request.security() while using barmerge.lookahead_on as the `lookahead` argument, the `expression` argument should be offset with the history-referencing operator to prevent lookahead bias on historical bars. However, the call in this script's example code enables lookahead without offsetting the `expression` because the script displays results only on the last historical bar and all realtime bars, where there is no future data to leak into the past. This call ensures the displayed results use the latest data available from the context on realtime bars.
Look first. Then leap.
█ EXPORTED TYPES
Data
A structure for storing successive timestamps and corresponding values from a dataset.
Fields:
times (array) : An "int" array containing a UNIX timestamp for each value in the `values` array.
values (array) : A "float" array containing values corresponding to the timestamps in the `times` array.
█ EXPORTED FUNCTIONS
getArrayFromString(str)
Splits a "string" into an array of substrings using the comma (`,`) as the delimiter. The function trims surrounding whitespace characters from each substring, and it excludes empty substrings from the result.
Parameters:
str (series string) : The "string" to split into an array based on its commas.
Returns: (array) An array of trimmed substrings from the specified `str`.
periodToTimestamp(period, referenceTime)
Calculates a UNIX timestamp representing the point offset behind a reference time by the amount of time within the specified `period`.
Parameters:
period (series string) : The period string, which determines the time offset of the returned timestamp. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the `referenceTime` value's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
referenceTime (series int) : The millisecond UNIX timestamp from which to calculate the offset time.
Returns: (int) A millisecond UNIX timestamp representing the offset time point behind the `referenceTime`.
collectData(source, timeOffsetLimit, timeframeLimit)
Collects `source` and `time` data successively across bars. The function stores the information within a `Data` object for use in other exported functions/methods, such as `valueAtTimeOffset()` and `valueAtPeriodOffset()`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to collect. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: (Data) A `Data` object containing collected `source` values and corresponding timestamps over the allowed time range.
method valueAtTime(data, timestamp)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest timestamp closest to the specified `timestamp`. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
timestamp (series int) : The millisecond UNIX timestamp to search. The function returns data for the earliest saved timestamp that is closest to the value.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to the specified `timestamp` ("int").
valueAtTime(source, timestamp, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to the specified `timestamp`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timestamp (series int) : The millisecond UNIX timestamp to search. The function returns data for the earliest bar whose timestamp is closest to the value.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : (simple string) Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to the specified `timestamp` ("int").
- The current bar's `source` value ("float").
method valueAtTimeOffset(data, timeOffset)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest saved timestamp closest to `timeOffset` milliseconds behind the current bar's opening time. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
timeOffset (series int) : The millisecond offset behind the bar's opening time. The function returns data for the earliest saved timestamp that is closest to the calculated offset time.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to `timeOffset` milliseconds before the current bar's opening time ("int").
valueAtTimeOffset(source, timeOffset, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to `timeOffset` milliseconds behind the current bar's opening time. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffset (series int) : The millisecond offset behind the bar's opening time. The function returns data for the earliest bar's timestamp that is closest to the calculated offset time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to `timeOffset` milliseconds before the current bar's opening time ("int").
- The current bar's `source` value ("float").
method valueAtPeriodOffset(data, period)
(Overload 1 of 2) Retrieves value and time data from a `Data` object's fields at the index of the earliest timestamp closest to a calculated offset behind the current bar's opening time. The calculated offset represents the amount of time covered by the specified `period`. Callable as a method or a function.
Parameters:
data (series Data) : The `Data` object containing the collected time and value data.
period (series string) : The period string, which determines the calculated time offset. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
Returns: ( ) A tuple containing the following data from the `Data` object:
- The stored value corresponding to the identified timestamp ("float").
- The earliest saved timestamp that is closest to the calculated offset behind the bar's opening time ("int").
valueAtPeriodOffset(source, period, timeOffsetLimit, timeframeLimit)
(Overload 2 of 2) Retrieves `source` and time information for the earliest bar whose opening timestamp is closest to a calculated offset behind the current bar's opening time. The calculated offset represents the amount of time covered by the specified `period`. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
period (series string) : The period string, which determines the calculated time offset. The specified argument must contain a unit and an optional multiplier (e.g., "1Y", "3M", "2W", "YTD"). Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple containing the following data:
- The `source` value corresponding to the identified timestamp ("float").
- The earliest bar's timestamp that is closest to the calculated offset behind the current bar's opening time ("int").
- The current bar's `source` value ("float").
getDataAtTimes(timestamps, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to one of the UNIX timestamps specified in the `timestamps` array. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
timestamps (array) : An array of "int" values representing UNIX timestamps. The function retrieves `source` and time data for each element in this array.
source (series float) : The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each item in the `timestamps` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").
getDataAtTimeOffsets(timeOffsets, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to one of the time offsets specified in the `timeOffsets` array. Each offset in the array represents the absolute number of milliseconds behind the current bar's opening time. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
timeOffsets (array) : An array of "int" values representing the millisecond time offsets used in the search. The function retrieves `source` and time data for each element in this array. For example, the array ` ` specifies that the function returns data for the timestamps closest to one day and one week behind the current bar's opening time.
source (float) : (series float) The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each offset specified in the `timeOffsets` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").
getDataAtPeriodOffsets(periods, source, timeOffsetLimit, timeframeLimit)
Retrieves `source` and time information for each bar whose opening timestamp is the earliest one closest to a calculated offset behind the current bar's opening time. Each calculated offset represents the amount of time covered by a period specified in the `periods` array. Any call to this function cannot execute more than once per bar or realtime tick.
Parameters:
periods (array) : An array of period strings, which determines the time offsets used in the search. The function retrieves `source` and time data for each element in this array. For example, the array ` ` specifies that the function returns data for the timestamps closest to one day, week, and month behind the current bar's opening time. Each "string" in the array must contain a unit and an optional multiplier. Supported units are:
- "Y" for years.
- "M" for months.
- "W" for weeks.
- "D" for days.
- "YTD" (Year-to-date) for the span from the start of the current bar's year in the exchange time zone. An argument with this unit cannot contain a multiplier.
source (float) : (series float) The source series to analyze. The function stores each value in the series with an associated timestamp representing its corresponding bar's opening time.
timeOffsetLimit (simple int) : Optional. A time offset (range) in milliseconds. If specified, the function limits the collected data to the maximum number of bars covered by the range, with a minimum of one bar. If the call includes a non-empty `timeframeLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
timeframeLimit (simple string) : Optional. A valid timeframe string. If specified and not empty, the function limits the collected data to the maximum number of bars covered by the timeframe, with a minimum of one bar. If the call includes a non-na `timeOffsetLimit` value, the function limits the data using the largest number of bars covered by the two ranges. The default is `na`.
Returns: ( ) A tuple of the following data:
- An array containing a `source` value for each identified timestamp (array).
- An array containing an identified timestamp for each period specified in the `periods` array (array).
- The current bar's `source` value ("float").
- The symbol's description from `syminfo.description` ("string").

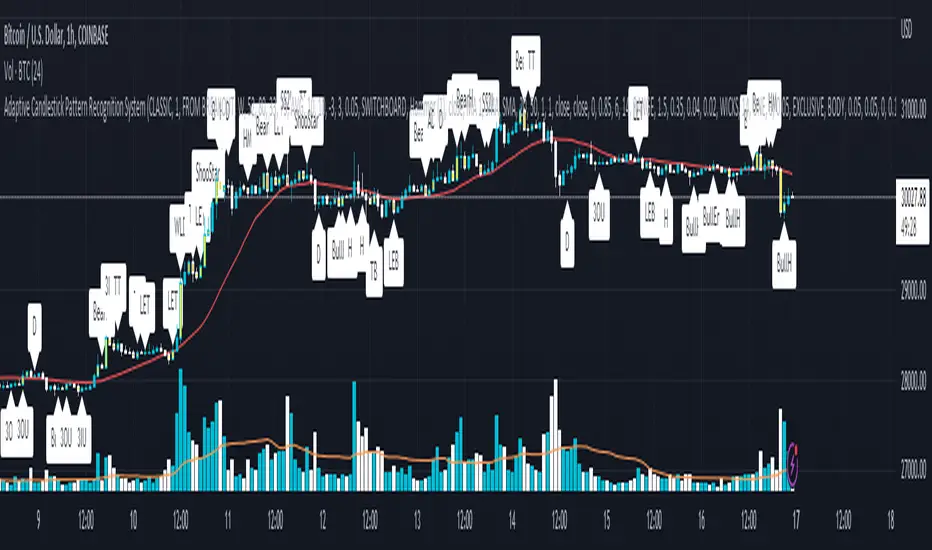
Adaptive Candlestick Pattern Recognition System█ INTRODUCTION
Nearly three years in the making, intermittently worked on in the few spare hours of weekends and time off, this is a passion project I undertook to flesh out my skills as a computer programmer. This script currently recognizes 85 different candlestick patterns ranging from one to five candles in length. It also performs statistical analysis on those patterns to determine prior performance and changes the coloration of those patterns based on that performance. In searching TradingView's script library for scripts similar to this one, I had found a handful. However, when I reviewed the ones which were open source, I did not see many that truly captured the power of PineScrypt or leveraged the way it works to create efficient and reliable code; one of the main driving factors for releasing this 5,000+ line behemoth open sourced.
Please take the time to review this description and source code to utilize this script to its fullest potential.
█ CONCEPTS
This script covers the following topics: Candlestick Theory, Trend Direction, Higher Timeframes, Price Analysis, Statistic Analysis, and Code Design.
Candlestick Theory - This script focuses solely on the concept of Candlestick Theory: arrangements of candlesticks may form certain patterns that can potentially influence the future price action of assets which experience those patterns. A full list of patterns (grouped by pattern length) will be in its own section of this description. This script contains two modes of operation for identifying candlestick patterns, 'CLASSIC' and 'BREAKOUT'.
CLASSIC: In this mode, candlestick patterns will be identified whenever they appear. The user has a wide variety of inputs to manipulate that can change how certain patterns are identified and even enable alerts to notify themselves when these patterns appear. Each pattern selected to appear will have their Profit or Loss (P/L) calculated starting from the first candle open succeeding the pattern to a candle close specified some number of candles ahead. These P/L calculations are then collected for each pattern, and split among partitions of prior price action of the asset the script is currently applied to (more on that in Higher Timeframes ).
BREAKOUT: In this mode, P/L calculations are held off until a breakout direction has been confirmed. The user may specify the number of candles ahead of a pattern's appearance (from one to five) that a pattern has to confirm a breakout in either an upward or downward direction. A breakout is constituted when there is a candle following the appearance of the pattern that closes above/at the highest high of the pattern, or below/at its lowest low. Only then will percent return calculations be performed for the pattern that's been identified, and these percent returns are broken up not only by the partition they had appeared in but also by the breakout direction itself. Patterns which do not breakout in either direction will be ignored, along with having their labels deleted.
In both of these modes, patterns may be overridden. Overrides occur when a smaller pattern has been detected and ends up becoming one (or more) of the candles of a larger pattern. A key example of this would be the Bearish Engulfing and the Three Outside Down patterns. A Three Outside Down necessitates a Bearish Engulfing as the first two candles in it, while the third candle closes lower. When a pattern is overridden, the return for that pattern will no longer be tracked. Overrides will not occur if the tail end of a larger pattern occurs at the beginning of a smaller pattern (Ex: a Bullish Engulfing occurs on the third candle of a Three Outside Down and the candle immediately following that pattern, the Three Outside Down pattern will not be overridden).
Important Functionality Note: These patterns are only searched for at the most recently closed candle, not on the currently closing candle, which creates an offset of one for this script's execution. (SEE LIMITATIONS)
Trend Direction - Many of the patterns require a trend direction prior to their appearance. Noting TradingView's own publication of candlestick patterns, I utilize a similar method for determining trend direction. Moving Averages are used to determine which trend is currently taking place for candlestick patterns to be sought out. The user has access to two Moving Averages which they may individually modify the following for each: Moving Average type (list of 9), their length, width, source values, and all variables associated with two special Moving Averages (Least Squares and Arnaud Legoux).
There are 3 settings for these Moving Averages, the first two switch between the two Moving Averages, and the third uses both. When using individual Moving Averages, the user may select a 'price point' to compare against the Moving Average (default is close). This price point is compared to the Moving Average at the candles prior to the appearance of candle patterns. Meaning: The close compared to the Moving Average two candles behind determines the trend direction used for Candlestick Analysis of one candle patterns; three candles behind for two candle patterns and so on. If the selected price point is above the Moving Average, then the current trend is an 'uptrend', 'downtrend' otherwise.
The third setting using both Moving Averages will compare the lengths of each, and trend direction is determined by the shorter Moving Average compared to the longer one. If the shorter Moving Average is above the longer, then the current trend is an 'uptrend', 'downtrend' otherwise. If the lengths of the Moving Averages are the same, or both Moving Averages are Symmetrical, then MA1 will be used by default. (SEE LIMITATIONS)
Higher Timeframes - This script employs the use of Higher Timeframes with a few request.security calls. The purpose of these calls is strictly for the partitioning of an asset's chart, splitting the returns of patterns into three separate groups. The four inputs in control of this partitioning split the chart based on: A given resolution to grab values from, the length of time in that resolution, and 'Upper' and 'Lower Limits' which split the trading range provided by that length of time in that resolution that forms three separate groups. The default values for these four inputs will partition the current chart by the yearly high-low range where: the 'Upper' partition is the top 20% of that trading range, the 'Middle' partition is 80% to 33% of the trading range, and the 'Lower' partition covers the trading range within 33% of the yearly low.
Patterns which are identified by this script will have their returns grouped together based on which partition they had appeared in. For example, a Bullish Engulfing which occurs within a third of the yearly low will have its return placed separately from a Bullish Engulfing that occurred within 20% of the yearly high. The idea is that certain patterns may perform better or worse depending on when they had occurred during an asset's trading range.
Price Analysis - Price Analysis is a major part of this script's functionality as it can fundamentally change how patterns are shown to the user. The settings related to Price Analysis include setting the number of candles ahead of a pattern's appearance to determine the return of that pattern. In 'BREAKOUT' mode, an additional setting allows the user to specify where the P/L calculation will begin for a pattern that had appeared and confirmed. (SEE LIMITATIONS)
The calculation for percent returns of patterns is illustrated with the following pseudo-code (CLASSIC mode, this is a simplified version of the actual code):
type patternObj
int ID
int partition
type returnsArray
float returns
// No pattern found = na returned
patternObj TEST_VAL = f_FindPattern()
priorTestVal = TEST_VAL
if not na( priorTestVal )
pnlMatrixRow = priorTestVal.ID
pnlMatrixCol = priorTestVal.partition
matrixReturn = matrix.get(PERCENT_RETURNS, pnlMatrixRow, pnlMatrixCol)
percentReturn = ( (close - open ) / open ) * 100%
array.push(matrixReturn.returns, percentReturn)
Statistic Analysis - This script uses Pine's built-in array functions to conduct the Statistic Analysis for patterns. When a pattern is found and its P/L calculation is complete, its return is added to a 'Return Array' User-Defined-Type that contains numerous fields which retain information on a pattern's prior performance. The actual UDT is as follows:
type returnArray
float returns = na
int size = 0
float avg = 0
float median = 0
float stdDev = 0
int polarities = na
All values within this UDT will be updated when a return is added to it (some based on user input). The array.avg , array.median and array.stdev will be ran and saved into their respective fields after a return is placed in the 'returns' array. The 'polarities' integer array is what will be changed based on user input. The user specifies two different percentages that declare 'Positive' and 'Negative' returns for patterns. When a pattern returns above, below, or in between these two values, different indices of this array will be incremented to reflect the kind of return that pattern had just experienced.
These values (plus the full name, partition the pattern occurred in, and a 95% confidence interval of expected returns) will be displayed to the user on the tooltip of the labels that identify patterns. Simply scroll over the pattern label to view each of these values.
Code Design - Overall this script is as much of an art piece as it is functional. Its design features numerous depictions of ASCII Art that illustrate what is being attempted by the functions that identify patterns, and an incalculable amount of time was spent rewriting portions of code to improve its efficiency. Admittedly, this final version is nearly 1,000 lines shorter than a previous version (one which took nearly 30 seconds after compilation to run, and didn't do nearly half of what this version does). The use of UDTs, especially the 'patternObj' one crafted and redesigned from the Hikkake Hunter 2.0 I published last month, played a significant role in making this script run efficiently. There is a slight rigidity in some of this code mainly around pattern IDs which are responsible for displaying the abbreviation for patterns (as well as the full names under the tooltips, and the matrix row position for holding returns), as each is hard-coded to correspond to that pattern.
However, one thing I would like to mention is the extensive use of global variables for pattern detection. Many scripts I had looked over for ideas on how to identify candlestick patterns had the same idea; break the pattern into a set of logical 'true/false' statements derived from historically referencing candle OHLC values. Some scripts which identified upwards of 20 to 30 patterns would reference Pine's built-in OHLC values for each pattern individually, potentially requesting information from TradingView's servers numerous times that could easily be saved into a variable for re-use and only requested once per candle (what this script does).
█ FEATURES
This script features a massive amount of switches, options, floating point values, detection settings, and methods for identifying/tailoring pattern appearances. All modifiable inputs for patterns are grouped together based on the number of candles they contain. Other inputs (like those for statistics settings and coloration) are grouped separately and presented in a way I believe makes the most sense.
Not mentioned above is the coloration settings. One of the aims of this script was to make patterns visually signify their behavior to the user when they are identified. Each pattern has its own collection of returns which are analyzed and compared to the inputs of the user. The user may choose the colors for bullish, neutral, and bearish patterns. They may also choose the minimum number of patterns needed to occur before assigning a color to that pattern based on its behavior; a color for patterns that have not met this minimum number of occurrences yet, and a color for patterns that are still processing in BREAKOUT mode.
There are also an additional three settings which alter the color scheme for patterns: Statistic Point-of-Reference, Adaptive coloring, and Hard Limiting. The Statistic Point-of-Reference decides which value (average or median) will be compared against the 'Negative' and 'Positive Return Tolerance'(s) to guide the coloration of the patterns (or for Adaptive Coloring, the generation of a color gradient).
Adaptive Coloring will have this script produce a gradient that patterns will be colored along. The more bullish or bearish a pattern is, the further along the gradient those patterns will be colored starting from the 'Neutral' color (hard lined at the value of 0%: values above this will be colored bullish, bearish otherwise). When Adaptive Coloring is enabled, this script will request the highest and lowest values (these being the Statistic Point-of-Reference) from the matrix containing all returns and rewrite global variables tied to the negative and positive return tolerances. This means that all patterns identified will be compared with each other to determine bullish/bearishness in Adaptive Coloring.
Hard Limiting will prevent these global variables from being rewritten, so patterns whose Statistic Point-of-Reference exceed the return tolerances will be fully colored the bullish or bearish colors instead of a generated gradient color. (SEE LIMITATIONS)
Apart from the Candle Detection Modes (CLASSIC and BREAKOUT), there's an additional two inputs which modify how this script behaves grouped under a "MASTER DETECTION SETTINGS" tab. These two "Pattern Detection Settings" are 'SWITCHBOARD' and 'TARGET MODE'.
SWITCHBOARD: Every single pattern has a switch that is associated with its detection. When a switch is enabled, the code which searches for that pattern will be run. With the Pattern Detection Setting set to this, all patterns that have their switches enabled will be sought out and shown.
TARGET MODE: There is an additional setting which operates on top of 'SWITCHBOARD' that singles out an individual pattern the user specifies through a drop down list. The names of every pattern recognized by this script will be present along with an identifier that shows the number of candles in that pattern (Ex: " (# candles)"). All patterns enabled in the switchboard will still have their returns measured, but only the pattern selected from the "Target Pattern" list will be shown. (SEE LIMITATIONS)
The vast majority of other features are held in the one, two, and three candle pattern sections.
For one-candle patterns, there are:
3 — Settings related to defining 'Tall' candles:
The number of candles to sample for previous candle-size averages.
The type of comparison done for 'Tall' Candles: Settings are 'RANGE' and 'BODY'.
The 'Tolerance' for tall candles, specifying what percent of the 'average' size candles must exceed to be considered 'Tall'.
When 'Tall Candle Setting' is set to RANGE, the high-low ranges are what the current candle range will be compared against to determine if a candle is 'Tall'. Otherwise the candle bodies (absolute value of the close - open) will be compared instead. (SEE LIMITATIONS)
Hammer Tolerance - How large a 'discarded wick' may be before it disqualifies a candle from being a 'Hammer'.
Discarded wicks are compared to the size of the Hammer's candle body and are dependent upon the body's center position. Hammer bodies closer to the high of the candle will have the upper wick used as its 'discarded wick', otherwise the lower wick is used.
9 — Doji Settings, some pulled from an old Doji Hunter I made a while back:
Doji Tolerance - How large the body of a candle may be compared to the range to be considered a 'Doji'.
Ignore N/S Dojis - Turns off Trend Direction for non-special Dojis.
GS/DF Doji Settings - 2 Inputs that enable and specify how large wicks that typically disqualify Dojis from being 'Gravestone' or 'Dragonfly' Dojis may be.
4 Settings related to 'Long Wick Doji' candles detailed below.
A Tolerance for 'Rickshaw Man' Dojis specifying how close the center of the body must be to the range to be valid.
The 4 settings the user may modify for 'Long Legged' Dojis are: A Sample Base for determining the previous average of wicks, a Sample Length specifying how far back to look for these averages, a Behavior Setting to define how 'Long Legged' Dojis are recognized, and a tolerance to specify how large in comparison to the prior wicks a Doji's wicks must be to be considered 'Long Legged'.
The 'Sample Base' list has two settings:
RANGE: The wicks of prior candles are compared to their candle ranges and the 'wick averages' will be what the average percent of ranges were in the sample.
WICKS: The size of the wicks themselves are averaged and returned for comparing against the current wicks of a Doji.
The 'Behavior' list has three settings:
ONE: Only one wick length needs to exceed the average by the tolerance for a Doji to be considered 'Long Legged'.
BOTH: Both wick lengths need to exceed the average of the tolerance of their respective wicks (upper wicks are compared to upper wicks, lower wicks compared to lower) to be considered 'Long Legged'.
AVG: Both wicks and the averages of the previous wicks are added together, divided by two, and compared. If the 'average' of the current wicks exceeds this combined average of prior wicks by the tolerance, then this would constitute a valid 'Long Legged' Doji. (For Dojis in general - SEE LIMITATIONS)
The final input is one related to candle patterns which require a Marubozu candle in them. The two settings for this input are 'INCLUSIVE' and 'EXCLUSIVE'. If INCLUSIVE is selected, any opening/closing variant of Marubozu candles will be allowed in the patterns that require them.
For two-candle patterns, there are:
2 — Settings which define 'Engulfing' parameters:
Engulfing Setting - Two options, RANGE or BODY which sets up how one candle may 'engulf' the previous.
Inclusive Engulfing - Boolean which enables if 'engulfing' candles can be equal to the values needed to 'engulf' the prior candle.
For the 'Engulfing Setting':
RANGE: If the second candle's high-low range completely covers the high-low range of the prior candle, this is recognized as 'engulfing'.
BODY: If the second candle's open-close completely covers the open-close of the previous candle, this is recognized as 'engulfing'. (SEE LIMITATIONS)
4 — Booleans specifying different settings for a few patterns:
One which allows for 'opens within body' patterns to let the second candle's open/close values match the prior candles' open/close.
One which forces 'Kicking' patterns to have a gap if the Marubozu setting is set to 'INCLUSIVE'.
And Two which dictate if the individual candles in 'Stomach' patterns need to be 'Tall'.
8 — Floating point values which affect 11 different patterns:
One which determines the distance the close of the first candle in a 'Hammer Inverted' pattern must be to the low to be considered valid.
One which affects how close the opens/closes need to be for all 'Lines' patterns (Bull/Bear Meeting/Separating Lines).
One that allows some leeway with the 'Matching Low' pattern (gives a small range the second candle close may be within instead of needing to match the previous close).
Three tolerances for On Neck/In Neck patterns (2 and 1 respectively).
A tolerance for the Thrusting pattern which give a range the close the second candle may be between the midpoint and close of the first to be considered 'valid'.
A tolerance for the two Tweezers patterns that specifies how close the highs and lows of the patterns need to be to each other to be 'valid'.
The first On Neck tolerance specifies how large the lower wick of the first candle may be (as a % of that candle's range) before the pattern is invalidated. The second tolerance specifies how far up the lower wick to the close the second candle's close may be for this pattern. The third tolerance for the In Neck pattern determines how far into the body of the first candle the second may close to be 'valid'.
For the remaining patterns (3, 4, and 5 candles), there are:
3 — Settings for the Deliberation pattern:
A boolean which forces the open of the third candle to gap above the close of the second.
A tolerance which changes the proximity of the third candle's open to the second candle's close in this pattern.
A tolerance that sets the maximum size the third candle may be compared to the average of the first two candles.
One boolean value for the Two Crows patterns (standard and Upside Gapping) that forces the first two candles in the patterns to completely gap if disabled (candle 1's close < candle 2's low).
10 — Floating point values for the remaining patterns:
One tolerance for defining how much the size of each candle in the Identical Black Crows pattern may deviate from the average of themselves to be considered valid.
One tolerance for setting how close the opens/closes of certain three candle patterns may be to each other's opens/closes.*
Three floating point values that affect the Three Stars in the South pattern.
One tolerance for the Side-by-Side patterns - looks at the second and third candle closes.
One tolerance for the Stick Sandwich pattern - looks at the first and third candle closes.
A floating value that sizes the Concealing Baby Swallow pattern's 3rd candle wick.
Two values for the Ladder Bottom pattern which define a range that the third candle's wick size may be.
* This affects the Three Black Crows (non-identical) and Three White Soldiers patterns, each require the opens and closes of every candle to be near each other.
The first tolerance of the Three Stars in the South pattern affects the first candle body's center position, and defines where it must be above to be considered valid. The second tolerance specifies how close the second candle must be to this same position, as well as the deviation the ratio the candle body to its range may be in comparison to the first candle. The third restricts how large the second candle range may be in comparison to the first (prevents this pattern from being recognized if the second candle is similar to the first but larger).
The last two floating point values define upper and lower limits to the wick size of a Ladder Bottom's fourth candle to be considered valid.
█ HOW TO USE
While there are many moving parts to this script, I attempted to set the default values with what I believed may help identify the most patterns within reasonable definitions. When this script is applied to a chart, the Candle Detection Mode (along with the BREAKOUT settings) and all candle switches must be confirmed before patterns are displayed. All switches are on by default, so this gives the user an opportunity to pick which patterns to identify first before playing around in the settings.
All of the settings/inputs described above are meant for experimentation. I encourage the user to tweak these values at will to find which set ups work best for whichever charts they decide to apply these patterns to.
Refer to the patterns themselves during experimentation. The statistic information provided on the tooltips of the patterns are meant to help guide input decisions. The breadth of candlestick theory is deep, and this was an attempt at capturing what I could in its sea of information.
█ LIMITATIONS
DISCLAIMER: While it may seem a bit paradoxical that this script aims to use past performance to potentially measure future results, past performance is not indicative of future results . Markets are highly adaptive and often unpredictable. This script is meant as an informational tool to show how patterns may behave. There is no guarantee that confidence intervals (or any other metric measured with this script) are accurate to the performance of patterns; caution must be exercised with all patterns identified regardless of how much information regarding prior performance is available.
Candlestick Theory - In the name, Candlestick Theory is a theory , and all theories come with their own limits. Some patterns identified by this script may be completely useless/unprofitable/unpredictable regardless of whatever combination of settings are used to identify them. However, if I truly believed this theory had no merit, this script would not exist. It is important to understand that this is a tool meant to be utilized with an array of others to procure positive (or negative, looking at you, short sellers ) results when navigating the complex world of finance.
To address the functionality note however, this script has an offset of 1 by default. Patterns will not be identified on the currently closing candle, only on the candle which has most recently closed. Attempting to have this script do both (offset by one or identify on close) lead to more trouble than it was worth. I personally just want users to be aware that patterns will not be identified immediately when they appear.
Trend Direction - Moving Averages - There is a small quirk with how MA settings will be adjusted if the user inputs two moving averages of the same length when the "MA Setting" is set to 'BOTH'. If Moving Averages have the same length, this script will default to only using MA 1 regardless of if the types of Moving Averages are different . I will experiment in the future to alleviate/reduce this restriction.
Price Analysis - BREAKOUT mode - With how identifying patterns with a look-ahead confirmation works, the percent returns for patterns that break out in either direction will be calculated on the same candle regardless of if P/L Offset is set to 'FROM CONFIRMATION' or 'FROM APPEARANCE'. This same issue is present in the Hikkake Hunter script mentioned earlier. This does not mean the P/L calculations are incorrect , the offset for the calculation is set by the number of candles required to confirm the pattern if 'FROM APPEARANCE' is selected. It just means that these two different P/L calculations will complete at the same time independent of the setting that's been selected.
Adaptive Coloring/Hard Limiting - Hard Limiting is only used with Adaptive Coloring and has no effect outside of it. If Hard Limiting is used, it is recommended to increase the 'Positive' and 'Negative' return tolerance values as a pattern's bullish/bearishness may be disproportionately represented with the gradient generated under a hard limit.
TARGET MODE - This mode will break rules regarding patterns that are overridden on purpose. If a pattern selected in TARGET mode would have otherwise been absorbed by a larger pattern, it will have that pattern's percent return calculated; potentially leading to duplicate returns being included in the matrix of all returns recognized by this script.
'Tall' Candle Setting - This is a wide-reaching setting, as approximately 30 different patterns or so rely on defining 'Tall' candles. Changing how 'Tall' candles are defined whether by the tolerance value those candles need to exceed or by the values of the candle used for the baseline comparison (RANGE/BODY) can wildly affect how this script functions under certain conditions. Refer to the tooltip of these settings for more information on which specific patterns are affected by this.
Doji Settings - There are roughly 10 or so two to three candle patterns which have Dojis as a part of them. If all Dojis are disabled, it will prevent some of these larger patterns from being recognized. This is a dependency issue that I may address in the future.
'Engulfing' Setting - Functionally, the two 'Engulfing' settings are quite different. Because of this, the 'RANGE' setting may cause certain patterns that would otherwise be valid under textbook and online references/definitions to not be recognized as such (like the Upside Gap Two Crows or Three Outside down).
█ PATTERN LIST
This script recognizes 85 patterns upon initial release. I am open to adding additional patterns to it in the future and any comments/suggestions are appreciated. It recognizes:
15 — 1 Candle Patterns
4 Hammer type patterns: Regular Hammer, Takuri Line, Shooting Star, and Hanging Man
9 Doji Candles: Regular Dojis, Northern/Southern Dojis, Gravestone/Dragonfly Dojis, Gapping Up/Down Dojis, and Long-Legged/Rickshaw Man Dojis
White/Black Long Days
32 — 2 Candle Patterns
4 Engulfing type patterns: Bullish/Bearish Engulfing and Last Engulfing Top/Bottom
Dark Cloud Cover
Bullish/Bearish Doji Star patterns
Hammer Inverted
Bullish/Bearish Haramis + Cross variants
Homing Pigeon
Bullish/Bearish Kicking
4 Lines type patterns: Bullish/Bearish Meeting/Separating Lines
Matching Low
On/In Neck patterns
Piercing pattern
Shooting Star (2 Lines)
Above/Below Stomach patterns
Thrusting
Tweezers Top/Bottom patterns
Two Black Gapping
Rising/Falling Window patterns
29 — 3 Candle Patterns
Bullish/Bearish Abandoned Baby patterns
Advance Block
Collapsing Doji Star
Deliberation
Upside/Downside Gap Three Methods patterns
Three Inside/Outside Up/Down patterns (4 total)
Bullish/Bearish Side-by-Side patterns
Morning/Evening Star patterns + Doji variants
Stick Sandwich
Downside/Upside Tasuki Gap patterns
Three Black Crows + Identical variation
Three White Soldiers
Three Stars in the South
Bullish/Bearish Tri-Star patterns
Two Crows + Upside Gap variant
Unique Three River Bottom
3 — 4 Candle Patterns
Concealing Baby Swallow
Bullish/Bearish Three Line Strike patterns
6 — 5 Candle Patterns
Bullish/Bearish Breakaway patterns
Ladder Bottom
Mat Hold
Rising/Falling Three Methods patterns
█ WORKS CITED
Because of the amount of time needed to complete this script, I am unable to provide exact dates for when some of these references were used. I will also not provide every single reference, as citing a reference for each individual pattern and the place it was reviewed would lead to a bibliography larger than this script and its description combined. There were five major resources I used when building this script, one book, two websites (for various different reasons including patterns, moving averages, and various other articles of information), various scripts from TradingView's public library (including TradingView's own source code for *all* candle patterns ), and PineScrypt's reference manual.
Bulkowski, Thomas N. Encyclopedia of Candlestick Patterns . Hoboken, New Jersey: John Wiley & Sons Inc., 2008. E-book (google books).
Various. Numerous webpages. CandleScanner . 2023. online. Accessed 2020 - 2023.
Various. Numerous webpages. Investopedia . 2023. online. Accessed 2020 - 2023.
█ AKNOWLEDGEMENTS
I want to take the time here to thank all of my friends and family, both online and in real life, for the support they've given me over the last few years in this endeavor. My pets who tried their hardest to keep me from completing it. And work for the grit to continue pushing through until this script's completion.
This belongs to me just as much as it does anyone else. Whether you are an institutional trader, gold bug hedging against the dollar, retail ape who got in on a squeeze, or just parents trying to grow their retirement/save for the kids. This belongs to everyone.
Private Beta for new features to be tested can be found here .
Vires In Numeris
PVV StochRSI TrendAnother Price, Volume, Volatility Trend indicator. This one has an RSI factor to it.
Have fun and change what you want.
Adjusting the inputs to the timeframe traded on is encouraged.

MFI Volume Profile [Kodexius]The MFI Volume Profile indicator blends a classic volume profile with the Money Flow Index so you can see not only where volume traded, but also how strong the buying or selling pressure was at those prices. Instead of showing a simple horizontal histogram of volume, this tool adds a money flow dimension and turns the profile into a price volume momentum heat map.
The script scans a user controlled lookback window and builds a set of price levels between the lowest and highest price in that period. For every bar inside that window, its volume is distributed across the price levels that the bar actually touched, and that volume is combined with the bar’s MFI value. This creates a volume weighted average MFI for each price level, so every row of the profile knows both how much volume traded there and what the typical money flow condition was when that volume appeared.
On the chart, the indicator plots a stack of horizontal boxes to the right of current price. The length of each box represents the relative amount of volume at that price, while the color represents the average MFI there. Levels with stronger positive money flow will lean toward warmer shades, and levels with weaker or negative money flow will lean toward cooler or more neutral shades inside the configured MFI band. Each row is also labeled in the format Volume , so you can instantly read the exact volume and money flow value at that level instead of guessing.
This gives you a detailed map of where the market really cared about price, and whether that interest came with strong inflow or outflow. It can help you spot areas of accumulation, distribution, absorption, or exhaustion, and it does so in a compact visual that sits next to price without cluttering the candles themselves.
Features
Combined volume profile and MFI weighting
The indicator builds a volume profile over a user selected lookback and enriches each price row with a volume weighted average MFI. This lets you study both participation and money flow at the same price level.
Volume distributed across the bar price range
For every bar in the window, volume is not assigned to a single price. Instead, it is proportionally distributed across all price rows between the bar low and bar high. This creates a smoother and more realistic profile of where trading actually happened.
MFI based color gradient between 30 and 70
Each price row is colored according to its average MFI. The gradient is anchored between MFI values of 30 and 70, which covers typical oversold, neutral and overbought zones. This makes strong demand or distribution areas easier to spot visually.
Configurable structure resolution and depth
Main user inputs are the lookback length, the number of rows, the width of the profile in bars, and the label text size. You can quickly switch between coarse profiles for a big picture and higher resolution profiles for detailed structure.
Numeric labels with volume and MFI per row
Every box is labeled with the total volume at that level and the average MFI for that level, in the format Volume . This gives you exact values while still keeping the visual profile clean and compact.
Calculations
Money Flow Index calculation
currentMfi is calculated once using ta.mfi(hlc3, mfiLen) as usual,
Creation of the profileBins array
The script creates an array named profileBins that will hold one VPBin element per price row.
Each VPBin contains
volume which is the total volume accumulated at that price row
mfiProduct which is the sum of volume multiplied by MFI for that row
The loop;
for i = 0 to rowCount - 1 by 1
array.push(profileBins, VPBin.new(0.0, 0.0))
pre allocates a clean structure with zero values for all rows.
Finding highest and lowest price across the lookback
The script starts from the current bar high and low, then walks backward through the lookback window
for i = 0 to lookback - 1 by 1
highestPrice := math.max(highestPrice, high )
lowestPrice := math.min(lowestPrice, low )
After this loop, highestPrice and lowestPrice define the full price range covered by the chosen lookback.
Price range and step size for rows
The code computes
float rangePrice = highestPrice - lowestPrice
rangePrice := rangePrice == 0 ? syminfo.mintick : rangePrice
float step = rangePrice / rowCount
rangePrice is the total height of the profile in price terms. If the range is zero, the script replaces it with the minimum tick size for the symbol. Then step is the price height of each row. This step size is used to map any price into a row index.
Processing each bar in the lookback
For every bar index i inside the lookback, the script checks that currentMfi is not missing. If it is valid, it reads the bar high, low, volume and MFI
float barTop = high
float barBottom = low
float barVol = volume
float barMfi = currentMfi
Mapping bar prices to bin indices
The bar high and low are converted into row indices using the known lowestPrice and step
int indexTop = math.floor((barTop - lowestPrice) / step)
int indexBottom = math.floor((barBottom - lowestPrice) / step)
Then the indices are clamped into valid bounds so they stay between zero and rowCount - 1. This ensures that every bar contributes only inside the profile range
Splitting bar volume across all covered bins
Once the top and bottom indices are known, the script calculates how many rows the bar spans
int coveredBins = indexTop - indexBottom + 1
float volPerBin = barVol / coveredBins
float mfiPerBin = volPerBin * barMfi
Here the total bar volume is divided equally across all rows that the bar touches. For each of those rows, the same fraction of volume and volume times MFI is used.
Accumulating into each VPBin
Finally, a nested loop iterates from indexBottom to indexTop and updates the corresponding VPBin
for k = indexBottom to indexTop by 1
VPBin binData = array.get(profileBins, k)
binData.volume := binData.volume + volPerBin
binData.mfiProduct := binData.mfiProduct + mfiPerBin
Over all bars in the lookback window, each row builds up
total volume at that price range
total volume times MFI at that price range
Later, during the drawing stage, the script computes
avgMfi = bin.mfiProduct / bin.volume
for each row. This is the volume weighted average MFI used both for coloring the box and for the numeric MFI value shown in the label Volume .

EMA Smoothed Standard Error Bands-zrbb-EMA Smoothed Standard Error Bands-zrbb-
The Standard Error Bands (SEM) indicator is primarily used in market analysis to measure price volatility, assess trend strength, and identify potential market reversals or consolidation zones. Similar to Bollinger Bands, it is typically based on linear regression lines rather than simple moving averages, providing traders with a visual range of price fluctuations around its average trend.
Specific functions include:
* Measuring Volatility: The width of the SEM directly reflects market volatility. When price trends are stable, the bandwidth typically contracts, indicating that data points are clustered around the mean; conversely, when market volatility increases, the bandwidth expands, indicating greater price dispersion.
* Assessing Trend Strength and Direction: This indicator can show the direction of the current trend and assess its strength by observing the price's position within the bands. If the price consistently touches or trades near the boundary on one side of the band, it usually indicates a strong trend in that direction.
* Identifying Overbought/Oversold Signals: While not a strictly overbought/oversold indicator, when the price touches or breaks through the upper or lower band, it may indicate that the market is in a state of extreme volatility in the short term, potentially leading to a price pullback or reversal.
Predicting Potential Trend Ends or Consolidation: When the standard error band begins to expand significantly, it can be a signal that the momentum of the current trend is weakening, and the market may be about to enter a consolidation phase or the trend may be about to reverse.
Assisting Decision Making and Risk Management: Traders use the boundary lines as potential support and resistance levels to help determine entry and exit points or set stop-loss levels, thereby managing trading risk.
In summary, the standard error band is a dynamic volatility tool that helps traders better understand market behavior by quantifying the degree to which prices deviate from their predicted trend, providing an important reference, especially in judging the continuation of trends and potential turning points.
标准误差带(Standard Error Bands)指标在市场分析中主要用于衡量价格波动性、判断趋势强度以及识别潜在的市场反转或盘整区域。它类似于布林带(Bollinger Bands),但通常基于线性回归线而不是简单的移动平均线,为交易者提供了价格围绕其平均趋势波动的视觉范围。
具体作用包括:
衡量波动性:标准误差带的宽度直接反映了市场的波动性。当价格趋势稳定时,带宽通常会收缩,表明数据点聚集在均值附近;相反,当市场波动加剧时,带宽会扩张,表明价格离散程度增大。
判断趋势强度和方向:该指标可以显示当前趋势的方向,并通过观察价格在带内的位置来评估趋势的强度。如果价格持续触及或运行在某一侧的边界附近,通常意味着该方向的趋势强劲。
识别超买/超卖信号:虽然不是严格意义上的超买/超卖指标,但当价格触及或突破上轨或下轨时,可能预示着市场短期内处于极端的波动状态,可能会出现价格回调或反转。
预测潜在的趋势结束或盘整:当标准误差带开始显著扩张时,这可能是一个信号,表明当前趋势的动能正在减弱,市场可能即将进入盘整期或趋势即将反转。
辅助决策和风险管理:交易者利用边界线作为潜在的支撑位和阻力位,帮助确定进场、出场点位或设置止损水平,从而管理交易风险。
总之,标准误差带是一个动态的波动率工具,它通过量化价格偏离其预测趋势的程度,帮助交易者更清晰地理解市场行为,尤其是在判断趋势的持续性和潜在转折点方面提供了重要参考。

YM Ultimate SNIPER v5# YM Ultimate SNIPER v5 - Documentation & Trading Guide
## 🎯 Unified GRA + DeepFlow | YM/MYM Optimized
**TARGET: 3-7 High-Confluence Trades per Day**
---
## ⚡ QUICK START
```
┌─────────────────────────────────────────────────────────────────┐
│ YM ULTIMATE SNIPER v5 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ SIGNALS: │
│ S🎯 = S-Tier (50+ pts) → HOLD position │
│ A🎯 = A-Tier (25-49 pts) → SWING trade │
│ B🎯 = B-Tier (12-24 pts) → SCALP quick │
│ Z = Zone entry (price at FVG zone) │
│ │
│ SESSIONS (ET): │
│ LDN = 3:00-5:00 AM (London) │
│ NY = 9:30-11:30 AM (New York Open) │
│ PWR = 3:00-4:00 PM (Power Hour) │
│ │
│ COLORS: │
│ 🟩 Green zones = Bullish FVG (buy zone) │
│ 🟥 Red zones = Bearish FVG (sell zone) │
│ 🟣 Purple lines = Single prints (S/R levels) │
│ │
│ TABLE (Top Right): │
│ Pts = Candle point range │
│ Tier = S/A/B/X classification │
│ Vol = Volume ratio (green = good) │
│ Delta = Buy/Sell dominance │
│ Sess = Current session │
│ Zone = In FVG zone status │
│ Score = Confluence score /10 │
│ CVD = Cumulative delta direction │
│ R:R = Risk:Reward ratio │
│ │
└─────────────────────────────────────────────────────────────────┘
```
---
## 📋 VERSION 5 CHANGES
### What's New
- **Removed all imbalance code** - caused compilation errors
- **Simplified delta analysis** - uses candle structure instead of intrabar data
- **Cleaner confluence scoring** - 5 clear factors, max 10 points
- **Reliable table** - updates on last bar only, no flickering
- **Works on YM and MYM** - same logic applies to micro contracts
### Removed Features
- Candle-anchored imbalance markers
- Imbalance S/R zones
- Intrabar volume profile analysis
- POC visualization
### Kept & Improved
- Tier classification (S/A/B)
- FVG zone detection & visualization
- Single print detection
- Session windows with backgrounds
- Confluence scoring
- Stop/Target auto-calculation
- All alerts
---
## 🎯 SIGNAL TYPES
### Tier Signals (S🎯, A🎯, B🎯)
These are high-confluence signals that pass all filters:
| Tier | Points | Value/Contract | Action | Hold Time |
|------|--------|----------------|--------|-----------|
| **S** | 50+ | $250+ | HOLD | 2-5 min |
| **A** | 25-49 | $125-245 | SWING | 1-3 min |
| **B** | 12-24 | $60-120 | SCALP | 30-90 sec |
**Filters Required:**
1. Tier threshold met (points)
2. Volume ≥ 1.8x average
3. Delta dominance ≥ 62%
4. Body ratio ≥ 70%
5. Range ≥ 1.3x average
6. Proper wicks (no reversal wicks)
7. CVD confirmation (optional)
8. In trading session
### Zone Signals (Z)
Zone entries trigger when:
- Price is inside an FVG zone
- Delta shows dominance in zone direction
- Volume is above average
- In active session
- No tier signal already present
---
## 📊 CONFLUENCE SCORING
**Maximum Score: 10 points**
| Factor | Points | Condition |
|--------|--------|-----------|
| Tier | 1-3 | B=1, A=2, S=3 |
| In Zone | +2 | Price inside FVG zone |
| Strong Volume | +2 | Volume ≥ 2x average |
| Strong Delta | +2 | Delta ≥ 70% |
| CVD Momentum | +1 | CVD trending with signal |
**Score Interpretation:**
- **7-10**: Elite setup - full size
- **5-6**: Good setup - standard size
- **4**: Minimum threshold - reduced size
- **< 4**: No signal shown
---
## ⏰ SESSION WINDOWS
### London (3:00-5:00 AM ET)
- European institutional flow
- Character: Slow build-up, clean trends
- Expected trades: 1-2
- Best for: Zone entries, A/B tier
### NY Open (9:30-11:30 AM ET)
- Highest volume, most institutional activity
- Character: Initial balance, breakouts
- Expected trades: 2-3
- Best for: S/A tier, zone confluence
### Power Hour (3:00-4:00 PM ET)
- End-of-day rebalancing, MOC orders
- Character: Mean reversion or trend acceleration
- Expected trades: 1-2
- Best for: Zone entries, B tier scalps
---
## 🟩 FVG ZONES
### What Are FVG Zones?
Fair Value Gaps (FVGs) are price gaps between candles where price moved so fast that a gap was left. These gaps often act as support/resistance.
### Zone Requirements
- Gap size ≥ 25% of ATR
- Impulse candle has strong body (≥ 70%)
- Impulse candle is 1.5x average range
- Volume above average on impulse
- Created during active session
### Zone States
1. **Fresh** (bright color) - Just created, untested
2. **Tested** (gray) - Price touched zone midpoint
3. **Broken** (removed) - Price closed through zone
### Trading FVG Zones
| Zone | Approach From | Expected |
|------|--------------|----------|
| 🟩 Bull | Above (falling) | Support - look for bounce |
| 🟥 Bear | Below (rising) | Resistance - look for rejection |
---
## 🟣 SINGLE PRINTS
Single prints mark candles with:
- Range > 1.3x average
- Body > 70% of range
- Volume > 1.8x average
- Clear delta dominance
These become horizontal support/resistance lines extending into the future.
---
## 📊 TABLE REFERENCE
| Row | Label | Meaning |
|-----|-------|---------|
| 1 | Pts | Current candle point range |
| 2 | Tier | S/A/B/X classification |
| 3 | Vol | Volume ratio vs 20-bar average |
| 4 | Delta | Buy/Sell percentage dominance |
| 5 | Sess | Current session (LDN/NY/PWR/OFF) |
| 6 | Zone | In FVG zone (BULL/BEAR/---) |
| 7 | Score | Confluence score out of 10 |
| 8 | CVD | Delta momentum direction |
| 9 | R:R | Risk:Reward if signal active |
### Color Coding
- **Green/Lime**: Good, meets threshold
- **Yellow**: Caution, borderline
- **Red**: Bad, below threshold
- **Gray**: Inactive/neutral
---
## 🔧 SETTINGS GUIDE
### Tier Thresholds
| Setting | Default | Notes |
|---------|---------|-------|
| S-Tier | 50 pts | ~$250/contract |
| A-Tier | 25 pts | ~$125/contract |
| B-Tier | 12 pts | ~$60/contract |
### Sniper Filters
| Setting | Default | Notes |
|---------|---------|-------|
| Min Volume Ratio | 1.8x | Lower = more signals |
| Delta Dominance | 62% | Lower = more signals |
| Body Ratio | 70% | Higher = fewer, cleaner |
| Range Multiplier | 1.3x | Higher = fewer, bigger moves |
| CVD Confirm | On | Off = more signals |
### Recommended Configurations
**Conservative (3-4 trades/day):**
```
Min Confluence: 6
Volume Ratio: 2.0
Delta Threshold: 65%
Body Ratio: 75%
```
**Standard (5-7 trades/day):**
```
Min Confluence: 4
Volume Ratio: 1.8
Delta Threshold: 62%
Body Ratio: 70%
```
**Aggressive (7-10 trades/day):**
```
Min Confluence: 3
Volume Ratio: 1.5
Delta Threshold: 60%
Body Ratio: 65%
```
---
## ✓ ENTRY CHECKLIST
Before entering any trade:
1. ☐ Signal present (S🎯, A🎯, B🎯, or Z)
2. ☐ Session active (LDN, NY, or PWR)
3. ☐ Score ≥ 4 (preferably 6+)
4. ☐ Vol shows GREEN
5. ☐ Delta colored (not gray)
6. ☐ CVD arrow matches direction
7. ☐ Note stop/target lines
8. ☐ Execute at signal candle close
---
## ⛔ DO NOT TRADE
- Session shows "OFF"
- Score < 4
- Vol shows RED
- Delta gray (no dominance)
- Multiple conflicting signals
- Major news imminent (FOMC, NFP, CPI)
- Overnight session (11:30 PM - 3:00 AM ET)
---
## 🎯 POSITION SIZING
| Tier | Score | Size | Stop |
|------|-------|------|------|
| S (50+ pts) | 7+ | 100% | Below/above candle |
| A (25-49 pts) | 5-6 | 75% | Below/above candle |
| B (12-24 pts) | 4 | 50% | Below/above candle |
| Zone | Any | 50% | Beyond zone |
---
## 🚨 ALERTS
### Priority Alerts (Set These)
| Alert | Action |
|-------|--------|
| 🎯 S-TIER | Drop everything, check immediately |
| 🎯 A-TIER | Evaluate within 15 seconds |
| 🎯 B-TIER | Check if available |
| 🎯 ZONE | Good context entry |
### Info Alerts (Optional)
| Alert | Purpose |
|-------|---------|
| NEW BULL/BEAR FVG | Mark zones on mental map |
| SINGLE PRINT | Note for future S/R |
| SESSION OPEN | Prepare to trade |
---
## 📈 TRADE JOURNAL
```
DATE: ___________
SESSION: ☐ LDN ☐ NY ☐ PWR
TRADE:
├── Time: _______
├── Signal: S🎯 / A🎯 / B🎯 / Z
├── Direction: LONG / SHORT
├── Score: ___/10
├── Entry: _______
├── Stop: _______
├── Target: _______
├── In Zone: ☐ Yes ☐ No
├── Result: +/- ___ pts ($_____)
└── Notes: _______________________
DAILY:
├── Trades: ___
├── Wins: ___ | Losses: ___
├── Net P/L: $_____
└── Best setup: _______________________
```
---
## 🏆 GOLDEN RULES
> **"Wait for the session. Off-hours = noise."**
> **"Score 6+ is your edge. Anything less is gambling."**
> **"Zone + Tier = bread and butter combo."**
> **"One great trade beats five forced trades."**
> **"Leave every trade with money. YM gives you time."**
---
## 🔧 TROUBLESHOOTING
| Issue | Solution |
|-------|----------|
| No signals | Lower min score to 3-4 |
| Too many signals | Raise min score to 6+ |
| Zones cluttering | Reduce max zones to 8 |
| Missing sessions | Check timezone setting |
| Table not updating | Resize chart or refresh |
---
## 📝 TECHNICAL NOTES
- **Pine Script v6**
- **Works on**: YM, MYM, any Dow futures
- **Recommended TF**: 1-5 minute for day trading
- **Min TradingView Plan**: Free (no intrabar data required)
---
*© Alexandro Disla - YM Ultimate SNIPER v5*
*Clean Build | Proven Components Only*
