OPEN-SOURCE SCRIPT
تم تحديثه Quantile-Based Adaptive Detection
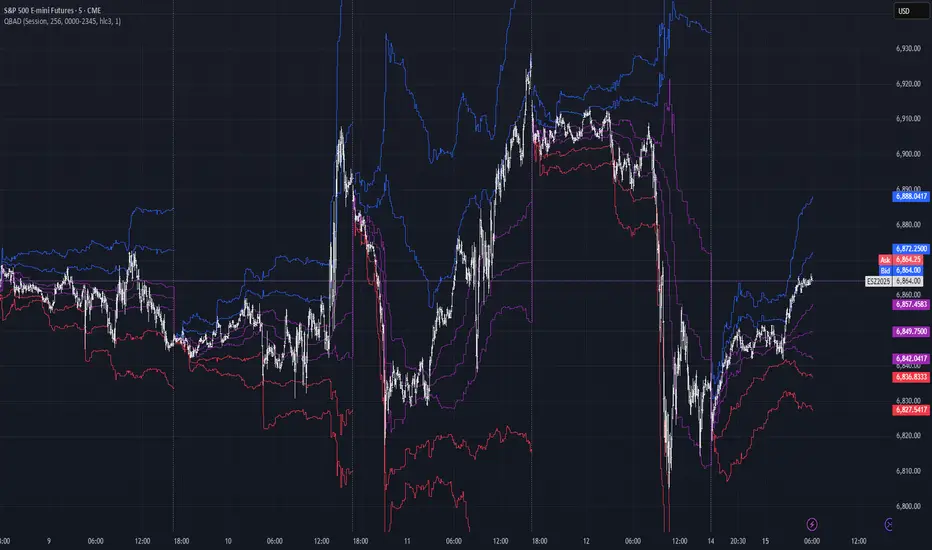
🙏🏻 Dedicated to John Tukey. He invented the boxplot, and I finalized it.
QBAD (Quantile-Based Adaptive Detection) is ‘the’ adaptive (also optionally weighted = ready for timeseries) boxplot with more senseful fences. Instead of hardcoded multipliers for outer fences, I base em on a set of quantile-based asymmetry metrics (you can view it as an ‘algorithmic’ counter part of central & standardized moments). So outer bands are Not hardcoded, not optimized, not cross-validated etc, simply calculated at O(nlogn).
You can use it literally everywhere in any context with any continuous data, in any task that requires statistical control, novelty || outlier detection, without worrying and doubting the sense in arbitrary chosen thresholds. Obviously, given the robust nature of quantiles, it would fit best the cases where data has problems.
The thresholds are:
…
The first part of the post is for locals xd, the second is for the wanderers/wizards/creators/<pick your definition>:
First part:
In terms of markets, mostly u gotta worry about dem instruments that represent crypto & FX assets: it’s either activity hence data sources there are decentralized, or data is fishy.
For a higher algocomplexity cost O(nlong), unlike MBAD that is 0(n), this thing (a control system in fact) works better with ishy data (contaminated with wrong values, incomplete, missing values etc). Read about the “breakdown point of an estimator” if you wanna understand it.
Even with good data, in cases when you have multiple instruments that represent the same asset, e.g. CL and BRN futures, and for some reason you wanna skip constructing a proper index of em (while you should), QBAD should be better put on each instrument individually.
Another reason to use this algo-based rather than math-based tool, might be in cases when data quality is all good, but the actual causal processes that generate the data are a bit inconsistent and/or possess ‘increased’ activity in a way. SO in high volatility periods, this tool should provide better.
In terms of built-ins you got 2 weightings: by sequence and by inferred volume delta. The former should be ‘On’ all the time when you work with timeseries, unless for a reason you want to consciously turn it off for a reason. The latter, you gotta keep it ‘On’ unless you apply the tool on another dataset that ain’t got that particular additional dimension.
Ain’t matter the way you gonna use it, moving windows, cumulative windows with or without anchors, that’s your freedom of will, but some stuff stays the same:
Another important thing, lately I started to see one kind of trend here on tradingview as well and in general in near quant sources, of applying averages, percentiles etc ‘on’ other stationary metrics, so called “indicators”. And I mean not for diagnostic or development reasons, for decision making xd
This is not the evil crime ofc, but hillbilly af, cuz the metrics are stationary it means that you can model em, fit a distribution, like do smth sharper. Worst case you have Bayesian statistics armed with high density intervals and equal tail intervals, and even some others. All this stuff is not hard to do, if u aint’t doing it, it’s on you.
So what I’m saying is it makes sense to apply QBAD on returns ‘of your strategy’, on volume delta, but Not on other metrics that already do calculations over their own moving windows.
...
Second part:
Looks like some finna start to have lil suspicions, that ‘maybe’ after all math entities in reality are more like blueprints, while actual representations are physical/mechanical/algorithmic. Std & centralized moments is a math entity that represents location, scale & asymmetry info, and we can use it no problem, when things are legit and consistent especially. Real world stuff tho sometimes deviates from that ideal, so we need smth more handy and real. Add to the mix the algo counter part of means: quantiles.
Unlike the legacy quantile-based asymmetry metrics from the previous century (check quantile skewness & kurtosis), I don’t use arbitrary sets of quantiles, instead we get a binary pattern that is totally geometric & natural (check the code if interested, I made it very damn explicit). In spirit with math based central & standardized moments, each consequent pair is wider empathizing tail info more and more for each higher order metric.
Unlike the classic box plot, where inner thresholds are quartiles and the rest are based on em, here the basis is median (minimises L1), I base inner thresholds on it, and we continue the pattern by basing the further set of levels on the previous set. So unlike the classic box plot, here we have coherency in construction, symmetry.
Another thing to pay attention to, tho for some reason ain’t many talk about it, it’s not conceptually right to think that “you got data and you apply std moments on it”. No, you apply it to ‘centered around smth’ data. That ‘smth’ should minimize L2 error in case of math, L1 error in case of algo, and L0 error in case of learning/MLish/optimizational/whatever-you-cal-it stuff. So in the case of L0, that’s actually the ‘mode’ of KDE, but that’s for another time. Anyways, in case of L2 it’s mean, so we center data around mean, and apply std moments on residuals. That’s the precise way of framing it. If you understand this, suddenly very interesting details like 0th and 1st central moments start to make sense. In case of quantiles, we center data around the median, and do further processing on residuals, same.
Oth moment (I call it init) is always 1, tho it’s interesting to extrapolate backwards the sequence for higher order moments construction, to understand how we actually end up with this zero.
1st moment (I call it bias) of residuals would be zero if you match centering and residuals analysis methods. But for some reason you didn’t do that (e.g centered data around midhinge or mean and applied QBAD on the centered data), you have to account for that bias.
Realizing stuff > understanding stuff
Learning 2981234 human invented fields < realizing the same unified principles how the Universe works
∞
QBAD (Quantile-Based Adaptive Detection) is ‘the’ adaptive (also optionally weighted = ready for timeseries) boxplot with more senseful fences. Instead of hardcoded multipliers for outer fences, I base em on a set of quantile-based asymmetry metrics (you can view it as an ‘algorithmic’ counter part of central & standardized moments). So outer bands are Not hardcoded, not optimized, not cross-validated etc, simply calculated at O(nlogn).
You can use it literally everywhere in any context with any continuous data, in any task that requires statistical control, novelty || outlier detection, without worrying and doubting the sense in arbitrary chosen thresholds. Obviously, given the robust nature of quantiles, it would fit best the cases where data has problems.
The thresholds are:
- Basis: the model of the data (median in our case);
- Deviations: represent typical spread around basis, together form “value” in general sense;
- Extensions: estimate data’s extremums via combination of quantile-based asymmetry metrics without relying on actual blunt min and max, together form “range” / ”frame”. Datapoints outside the frame/range are novelties or outliers;
- Limits: based also on quantile asymmetry metrics, estimate the bounds within which values can ‘ever’ emerge given the current data generating process stays the same, together form “field”. Datapoints outside the field are very rare, happen when a significant change/structural break happens in current data-generating process, or when a corrupt datapoint emerges.
…
The first part of the post is for locals xd, the second is for the wanderers/wizards/creators/<pick your definition>:
First part:
In terms of markets, mostly u gotta worry about dem instruments that represent crypto & FX assets: it’s either activity hence data sources there are decentralized, or data is fishy.
For a higher algocomplexity cost O(nlong), unlike MBAD that is 0(n), this thing (a control system in fact) works better with ishy data (contaminated with wrong values, incomplete, missing values etc). Read about the “breakdown point of an estimator” if you wanna understand it.
Even with good data, in cases when you have multiple instruments that represent the same asset, e.g. CL and BRN futures, and for some reason you wanna skip constructing a proper index of em (while you should), QBAD should be better put on each instrument individually.
Another reason to use this algo-based rather than math-based tool, might be in cases when data quality is all good, but the actual causal processes that generate the data are a bit inconsistent and/or possess ‘increased’ activity in a way. SO in high volatility periods, this tool should provide better.
In terms of built-ins you got 2 weightings: by sequence and by inferred volume delta. The former should be ‘On’ all the time when you work with timeseries, unless for a reason you want to consciously turn it off for a reason. The latter, you gotta keep it ‘On’ unless you apply the tool on another dataset that ain’t got that particular additional dimension.
Ain’t matter the way you gonna use it, moving windows, cumulative windows with or without anchors, that’s your freedom of will, but some stuff stays the same:
- Basis and deviations are “value” levels. From process control perspective, if you pls, it makes sense to Not only fade or push based on these levels, but to also do nothing when things are ambiguous and/or don’t require your intervention
- Extensions and limits are extreme levels. Here you either push or fade, doing nothing is not an option, these are decisive points in all the meanings
Another important thing, lately I started to see one kind of trend here on tradingview as well and in general in near quant sources, of applying averages, percentiles etc ‘on’ other stationary metrics, so called “indicators”. And I mean not for diagnostic or development reasons, for decision making xd
This is not the evil crime ofc, but hillbilly af, cuz the metrics are stationary it means that you can model em, fit a distribution, like do smth sharper. Worst case you have Bayesian statistics armed with high density intervals and equal tail intervals, and even some others. All this stuff is not hard to do, if u aint’t doing it, it’s on you.
So what I’m saying is it makes sense to apply QBAD on returns ‘of your strategy’, on volume delta, but Not on other metrics that already do calculations over their own moving windows.
...
Second part:
Looks like some finna start to have lil suspicions, that ‘maybe’ after all math entities in reality are more like blueprints, while actual representations are physical/mechanical/algorithmic. Std & centralized moments is a math entity that represents location, scale & asymmetry info, and we can use it no problem, when things are legit and consistent especially. Real world stuff tho sometimes deviates from that ideal, so we need smth more handy and real. Add to the mix the algo counter part of means: quantiles.
Unlike the legacy quantile-based asymmetry metrics from the previous century (check quantile skewness & kurtosis), I don’t use arbitrary sets of quantiles, instead we get a binary pattern that is totally geometric & natural (check the code if interested, I made it very damn explicit). In spirit with math based central & standardized moments, each consequent pair is wider empathizing tail info more and more for each higher order metric.
Unlike the classic box plot, where inner thresholds are quartiles and the rest are based on em, here the basis is median (minimises L1), I base inner thresholds on it, and we continue the pattern by basing the further set of levels on the previous set. So unlike the classic box plot, here we have coherency in construction, symmetry.
Another thing to pay attention to, tho for some reason ain’t many talk about it, it’s not conceptually right to think that “you got data and you apply std moments on it”. No, you apply it to ‘centered around smth’ data. That ‘smth’ should minimize L2 error in case of math, L1 error in case of algo, and L0 error in case of learning/MLish/optimizational/whatever-you-cal-it stuff. So in the case of L0, that’s actually the ‘mode’ of KDE, but that’s for another time. Anyways, in case of L2 it’s mean, so we center data around mean, and apply std moments on residuals. That’s the precise way of framing it. If you understand this, suddenly very interesting details like 0th and 1st central moments start to make sense. In case of quantiles, we center data around the median, and do further processing on residuals, same.
Oth moment (I call it init) is always 1, tho it’s interesting to extrapolate backwards the sequence for higher order moments construction, to understand how we actually end up with this zero.
1st moment (I call it bias) of residuals would be zero if you match centering and residuals analysis methods. But for some reason you didn’t do that (e.g centered data around midhinge or mean and applied QBAD on the centered data), you have to account for that bias.
Realizing stuff > understanding stuff
Learning 2981234 human invented fields < realizing the same unified principles how the Universe works
∞
ملاحظات الأخبار
New:- Extended data interval logic: now you have expanding windows anchored to session start, year start, and some more.
- Even tho QBAD has to be used with median as center, this way we minimize L1 distance, now it also uses bias (1st central moment) to adjust things in case u apply it on a center of data that is not mean
- I added a function that calculates weighted proportion of datapoints inside the value (value is area in between lower and upper deviations) vs all datapoints. The output is displayed as the rightmost gray number in the script's status line. If this number is < 0.45-0.5, it's a good idea to stop using QBAD and switch to PBAD (will release it soon). This is still experimental, but the logic is this: +- IQR/2 around median should cover at lest some decent amount of data. When it's not like that anymore, the methods looses power.
Misc:
- default settings are adjusted for general purpose use right away
- slightly better math of weighting by inferred volume delta weighting (becomes a thing only on very high resolutions)
- code adjusted for easier portability
نص برمجي مفتوح المصدر
بروح TradingView الحقيقية، قام مبتكر هذا النص البرمجي بجعله مفتوح المصدر، بحيث يمكن للمتداولين مراجعة وظائفه والتحقق منها. شكرا للمؤلف! بينما يمكنك استخدامه مجانًا، تذكر أن إعادة نشر الكود يخضع لقواعد الموقع الخاصة بنا.
Gor Dragongor
t.me/synchro1_channel
linkedin.com/company/synchro1
t.me/synchro1_channel
linkedin.com/company/synchro1
إخلاء المسؤولية
لا يُقصد بالمعلومات والمنشورات أن تكون، أو تشكل، أي نصيحة مالية أو استثمارية أو تجارية أو أنواع أخرى من النصائح أو التوصيات المقدمة أو المعتمدة من TradingView. اقرأ المزيد في شروط الاستخدام.
نص برمجي مفتوح المصدر
بروح TradingView الحقيقية، قام مبتكر هذا النص البرمجي بجعله مفتوح المصدر، بحيث يمكن للمتداولين مراجعة وظائفه والتحقق منها. شكرا للمؤلف! بينما يمكنك استخدامه مجانًا، تذكر أن إعادة نشر الكود يخضع لقواعد الموقع الخاصة بنا.
Gor Dragongor
t.me/synchro1_channel
linkedin.com/company/synchro1
t.me/synchro1_channel
linkedin.com/company/synchro1
إخلاء المسؤولية
لا يُقصد بالمعلومات والمنشورات أن تكون، أو تشكل، أي نصيحة مالية أو استثمارية أو تجارية أو أنواع أخرى من النصائح أو التوصيات المقدمة أو المعتمدة من TradingView. اقرأ المزيد في شروط الاستخدام.